
A proper release is a lot of work and a lot of steps. To ensure that the work is done well and quickly, it is a good idea to automate as many of them as possible.
Let’s talk about two steps in particular: the (automatic) numbering of the next version, and the generation of its changelog.
After having worked on a rather wide range of applications and libraries, our feedback is clear: Automating the release process pays off! When this process is automatic (or simply requires less work), you can do it more often. Hence you can release new functionalities (or fixes/patches) faster. And everybody wins.
The problem
Here we will use the semver numbering convention, which you may know.
As a reminder, with semver, a version number comes in the form X.Y.Z, or major.minor.patch. This system allows you to know at a glance if a library update introduces changes that require you to modify your code or not: minor or patch level updates preserve compatibility, but not major level ones.
Some dependency managers (like npm, pip, and many others) allow you to describe the compatibility of an application with specific versions of its dependencies, and in passing to ensure updates without " blowing everything up “ :P
Semantic versioning is good in theory, but in practice, you are not immune to trollish discussions when the time comes to release a new version. You often get a sentimental view of this famous X.Y.Z … Yet for an alternative point of view on the issue, you can read the sentimental versioning manifesto! (in English).
In short, choosing a version number is sometimes like an ordeal: multiple contributors (dev, product owner, …), waiting for a collaborator with the rights, lack of visibility on the content …
I faced this kind of problem and, after doing some research, I thought that we could automate all this.
How to automate
Continuous integration is one of the key elements when it comes to automating code delivery: one simple action on git triggers the production of an artifact (a container or a package for instance), launches a battery of tests, and produces a return. This return can contain: a success or error code, a test report, a code quality report, etc.
The question is: can we add to all this an automatic decision about whether to release or not a new version of the application, with its ad-hoc numbering (using semver), and why not a detailed changelog?
The answer is: yes, for instance by using semantic-release. There are other options, like semantic-delivery, but unfortunately I haven’t (yet) had the opportunity to test them all. Most of these systems work on the same principle.
The human management of the release is replaced by a tool that :
- inspects the history of commits since the previous version
- concludes a new version number following the semver rules
- generates a changelog for this new version
- applies the corresponding git tag
- creates a release in your advanced code manager (for example gitlab)
- optionally, launches a new continuous integration or deployment pipeline to take advantage of all this information.
Now let’s see a concrete example.
Using GitLab
At Enix, we use GitLab a lot internally. So my example will be based on this platform and on the usual .gitlab-ci.yaml file. Several strategies are possible:
- triggering when a merge is done on a defined branch (like
master) - triggering manually by pressing a button somewhere
- … other, depending on your needs and your decision organisation
We will show here the first technique. To do this, we create a dedicated job in the IC, which will be triggered when we want to update the application.
This is what the job used by the enix.io website looks like when the master branch is updated. After having generated the site (with Lektor) and tested its W3C compliance, we launch semantic-release:
semantic-release:
stage: release
image: enix/semantic-release:gitlab
script:
- npx semantic-release --ci
only:
- master
except:
- tags
In the example below, the tool analyzes the commits since the last version and concludes that the next version will be 1.30.0, ” yeah baby “:
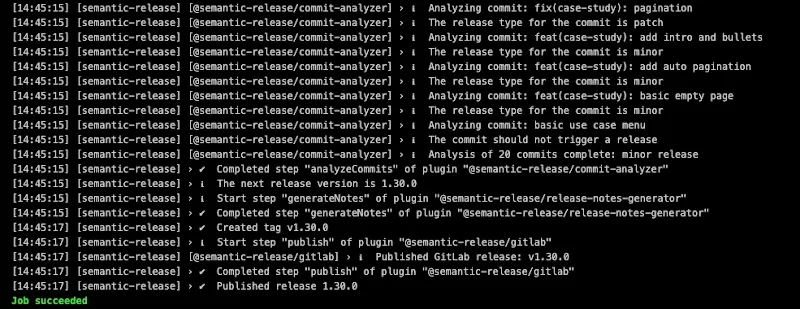
So you note that the machine works for you:
The release type for the commit is minorThe release type for the commit is patchCreated tag v1.30.0Completed step "generateNotes" ...
Then a deployment pipeline starts for this new version, until it lands in production on our Kubernetes cluster:
With as a bonus, the automatic creation of a GitLab release and its attached changelog :
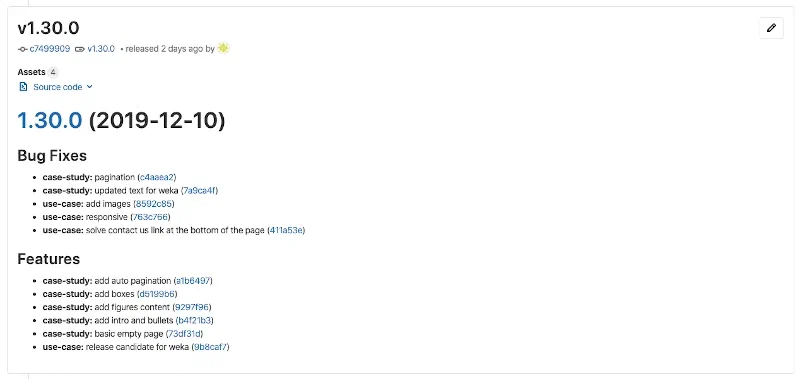
How far to automate and what are the limits
The functionalities listed above are available for most code managers, sometimes through plugins (GitHub) or sometimes with limitations (BitBucket). There are a good bunch of extensions here.
- No restrictions on your branch merge strategies as the tool only interprets commits since the last tag! But make sure you run the tests before triggering an automatic decision.
It’s not magic
Since semantic-release uses messages linked to the commits to determine the type of change, you have to follow a very specific convention for these messages.
By default, we use the Angular commit message convention. At a minimum, the first line of the commit must follow this formalism:
feat(blog): an article about semantic-release
Or else:
fix(blog): reword introduction
You have to make sure that the people who commit in git stick to it, otherwise … no new version triggered!
But it is enough to follow this convention to not have to worry about the numbering and the release of the versions.
To conclude
Once the automation is in place, and by following a (relatively simple) convention in your commit messages, you no longer need to perform a release by hand, with the various manual operations this implies.
More precisely: the final decision to change the version is broken down into multiple small decisions that took place very early before it (when the code was being produced).
All this will allow you to make your releases more often, in a reliable way, and thus in fine to deliver code faster without sacrificing its quality!
Do not miss our latest DevOps and Cloud Native blogposts! Follow Enix on Linkedin!