
Une release en bonne et due forme, c’est beaucoup de travail et pas mal d’étapes. Pour s’assurer que le travail est vite fait et bien fait, c’est une bonne idée d’en automatiser un maximum.
On va parler de deux étapes en particulier : la numérotation (automatique) de la prochaine version, et la génération de son changelog.
Après avoir travaillé sur un panel assez large d’applications et bibliothèques en tous genres, le retour d’expérience est clair : Automatiser le processus de release, ça rapporte gros! Quand le processus est automatique (ou simplement demande moins de travail), on peut le faire plus souvent. Donc on peut sortir des nouvelles fonctionalités (ou des correctifs) plus vite. Et tout le monde y gagne.
Le problème
On se propose ici d’utiliser la convention de numérotation semver, que vous connaissez peut-être.
Pour rappel, avec semver, un numéro de version est de la forme X.Y.Z, ou encore majeur.mineur.patch. Ce système permet de savoir en un coup d’œil si une mise à jour de bibliothèque introduit des changements nécessitant de modifier notre code ou non : les mises à jour de niveau mineur ou patch préservent la compatibilité, mais pas celles de niveau majeur.
Certains gestionnaires de dépendances (comme npm, pip, et bien d’autres) vous permettent de décrire la compatibilité d’une application avec des versions spécifiques de ses dépendances, et au passage d’assurer des mises à jours sans " tout péter “ :P
Le semantic versioning c’est bien en théorie, mais en pratique, nous ne sommes pas à l’abri des trolls discussions houleuses lorsque le moment de sortir une nouvelle version pointe le bout de son nez. On a souvent une vision sentimentale face à ce fameux X.Y.Z … Et pour un point de vue alternatif sur la question, on peut lire le manifeste du sentimental versioning ! (en anglais).
Bref, choisir un numéro de version ressemble parfois à un calvaire : multiples intervenant·e·s (dev, product owner, …), attente d’un collaborateur ayant les droits, manque de visibilité sur le contenu …
J’ai fait face à ce genre de problème et, après avoir fait quelques recherches, je me suis dit qu’on pouvait automatiser tout ça.
Comment automatiser
L’intégration continue est un des éléments clé dans l’automatisation autour du code : une simple action sur git déclenche la production d’un artéfact (un conteneur ou un paquetage par exemple), lance une batterie de test, et produit un retour. Un retour qui peut contenir : un code de succès ou d’erreur, un rapport de test, un rapport de qualité du code, etc.
La question est : peut-on ajouter à tout ça une prise de décision automatique quant à la sortie ou non d’une nouvelle version de l’application, avec sa numérotation ad-hoc (utilisant semver), et pourquoi pas un changelog détaillé ?
Réponse : oui, par exemple en utilisant semantic-release. Il existe d’autres options comme semantic-delivery mais je n’ai malheureusement pas (encore) eu l’occasion de toutes les tester. Ces systèmes fonctionnent pour la plupart selon le même principe.
La gestion humaine de la release est remplacée par un outil qui :
- inspecte l’historique des commits depuis la version précédente
- en conclue un nouveau numéro de version en suivant les règles semver
- génère un changelog pour cette nouvelle version
- applique le tag git correspondant
- crée une release dans votre gestionnaire de code avancé (par exemple gitlab)
- en option, lance un nouveau pipeline d’intégration ou déploiement continu pour profiter de toutes ces informations.
Voyons maintenant un exemple concret.
Avec GitLab
Chez Enix, on utilise beaucoup GitLab en interne. Mon exemple va donc s’appuyer sur cette plateforme et sur le fichier habituel .gitlab-ci.yaml. Plusieurs stratégies sont possibles :
- déclencher lors d’un merge sur une branche définie (comme
master) - déclencher à la main en appuyant sur un bouton quelque part
- … autre, selon votre besoin et votre structure de décision
On va ici montrer la première technique. Pour ça, on crée un job dédié dans la CI, qui se délenchera lorsqu’on souhaite mettre à jour l’appli.
Voilà à quoi ressemble le job utilisé par le site web enix.io lorsque la branche master est mise à jour. Après avoir généré le site (avec Lektor) et testé sa conformité W3C, on lance semantic-release :
semantic-release:
stage: release
image: enix/semantic-release:gitlab
script:
- npx semantic-release --ci
only:
- master
except:
- tags
Dans l’exemple ci-dessous, l’outil analyse les commits depuis la dernière version et en conclut que la prochaine version sera 1.30.0, ” yeah baby “ :
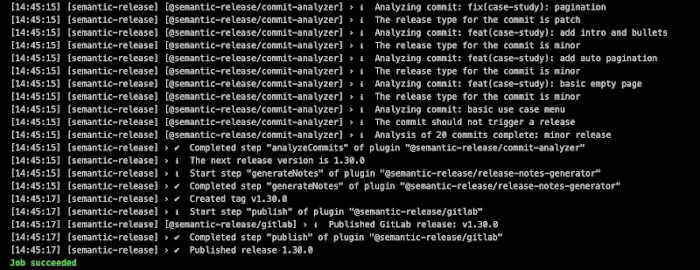
Vous notez que la machine travaille pour vous :
The release type for the commit is minorThe release type for the commit is patchCreated tag v1.30.0Completed step "generateNotes" ...
Puis, un pipeline de déploiement se met en marche pour cette nouvelle version, jusqu’à ce qu’elle atterrisse en production sur notre cluster Kubernetes :
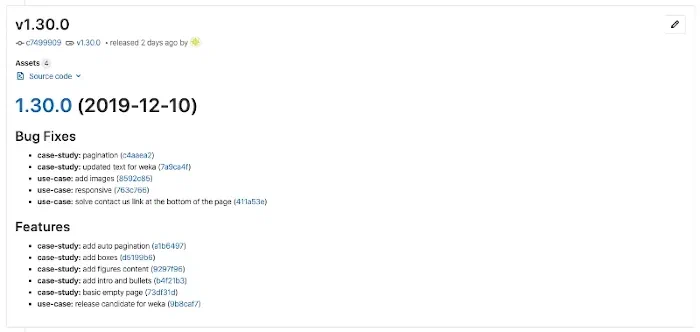
Avec en prime, la création automatique d’une release GitLab et son changelog attaché :
Jusqu’où automatiser et quelles sont les limites
Les fonctionnalités listées plus haut sont disponibles pour la plupart des gestionnaires de code, parfois au travers de plugins (GitHub) ou parfois avec des limitations (BitBucket). Il existe un bon paquet d’extensions ici.
Pas de restriction sur vos stratégies de merge de branche car l’outil se contente d’interpréter les commits depuis le dernier tag ! Mais assurez-vous de lancer les tests avant de déclencher une prise de décision automatique.
C’est pas magique
Puisque semantic-release utilise les messages liés au commits pour déterminer le type de changement, il faut suivre une convention bien précise pour ces messages.
Par défaut, on utilise la convention de message de commit d’Angular. Au minimum, il faut que la première ligne du commit suive ce formalisme :
feat(blog): an article about semantic-release
Ou encore:
fix(blog): reword introduction
Il faut s’assurer que les gens qui commit dans git s’y tiennent, sinon … pas de nouvelle version déclenchée !
Mais il suffit de suivre cette convention pour ne plus avoir besoin de se préoccuper de la numérotation et la release des versions.
Conclusions
Une fois l’automatisation en place, et en suivant une convention (relativement simple) dans nos messages de commit, nous n’avons plus besoin d’effectuer une release à la main, avec les diverses opérations manuelles que ça implique.
Plus précisément : la décision finale de changement de version est découpée en de multiples petites décisions ayant lieu bien avant (lorsque le code a été produit).
Tout cela nous permet de faire nos releases plus souvent, de manière fiable, et donc in fine de livrer du code plus vite sans sacrifier sa qualité !
Ne ratez pas nos prochains articles DevOps et Cloud Native! Suivez Enix sur Linkedin!