
Project background
At Enix, we manage hundreds of Kubernetes clusters for our customers and our own internal use. On cloud, on premises, big and small, from development to large-scale production deployments. One recurring challenge we face across all these environments is ensuring reliable Kubernetes image caching.
Every Kubernetes administrator has encountered, or will encounter, an issue related to container image retrieval. This may happen when you roll out an update to patch a security issue, fix a bug or rollback to a stable release after a faulty update. And then, surprise: on a few nodes of the cluster, some containers won’t start because the image can’t be pulled. The registry might be down, or having a bad day, or the image might have been removed, or you might be hitting your Docker Hub pull quota. Either way: you’re SOL (sadly out of luck).
After our team ran into that issue one time too many, we decided to try and fix it - hopefully for good. Our solution? A **Kubernetes container image cache ** that ensures any image pulled at least once into a cluster remains accessible.
And thus, kube-image-keeper (kuik) was born!
This article walks through the thought process behind kube-image-keeper, including our evaluation of existing solutions, the final architecture, and how you can start using it today.
Spoiler alert: we’ll talk about proxies, caches, CRD, kubernetes operators…
Before we dive in, here’s a short recap of what we wanted to address:
- Unavailability (outages or reduced performance) of public (SaaS) registries
- Pull limits enforced by some registries, such as Docker Hub’s rate limits (in particular with their free tier)
- Image removal due to storage policies, despite being actively used in clusters
We acknowledge that these issues can happen in both in-premises and cloud-based clusters, and wanted our solution to fit both scenarios without compromise, which means that we didn’t want to rely on cloud-specific services (like the availability of an object store) or datacenter-specific features (like L2 networks - not that it would have helped in that case anyway).
Evaluating Existing Kubernetes Image Caching Solutions
When we started the project in early 2022, we wanted to reuse existing components as much as possible rather than reinvent the wheel.
We found a few promising projects, basically typing “kubernetes images local caching" in our favorite web, either because they seemed to provide a stand-alone solution or because they could be combined with other to provide one:
kubernetes-image-puller: interesting idea, but not for us
kubernetes-image-puller is straight away set aside, after reading the doc and before testing, mainly because the supported images volume is too weak.
💡 Through this component, container images of interest must be retrieved and launched with the sleep command 720h (if this command is not used, images are downloaded BUT the container switches straight away to CrashLoopBackOff mode …) , in order to initialize pods, specifically started to contain the cached images, that will be used in order to serve the upcoming clusters requests.
💡 This design was partly revamped BUT the result still does not suit our needs.
💡 kubernetes-image-puller deploys a huge number of containers (one container per image and per node / uses a daemonset for the caching mechanism), to fulfill the caching feature.
Let’s take this example : With 5 nodes & 10 images in cache, we already have 50 containers within the cluster dedicated for the caching feature …
An “out of the box” solution with kube-fledged ?
We now start a testing phase with kube-fledged. This solution seems to stick to our needs & mind.
This project allows to set an images list, manually defined through CRDs, into the cache,. This implementation appears to be a solid foundation that we’ll enhance putting in place automated detection for images to be set in cache. At this stage, we target to delegate this task to customized code that will finally update the needed CRDs.
Unfortunately, we then understand that kube-fledged does not optimize the source registry calls (quite the opposite …) and over-consume the nodes local storage.
We feel we’ll never reach our target without embedding a local registry that up-streams as less as possible to source registries!
Tugger in harmony with Harbor ?
This first disappointing experience pushed us to refine our technical needs and think about other solutions. Finally, we decided to use the combination of Harbor (cache/registry) + Tugger (engine)
Below is the architecture diagram, associated to this new round :
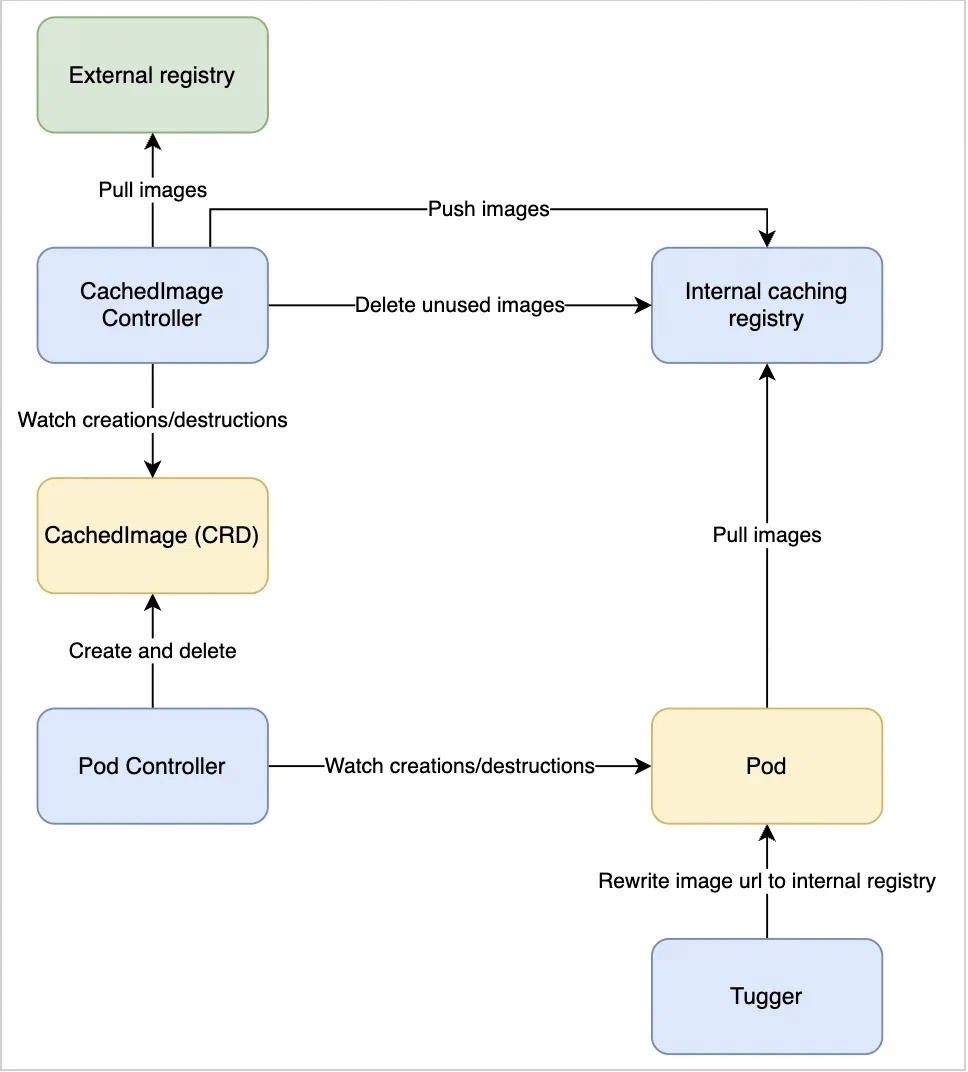
We hit the target BUT :
- Managing Harbor, a tool “full” of features and thus heavy during installation & configuration is “overkill” for our needs.
- Tugger comes with a blocking behavior (for us) regarding the users segregation of duties, not compatible with our approach.
💡 Tugger uses a single configuration file, defined through its Helm file values. It does not allow us to segregate “system” configurations (eg : exclude specific images from the caching system) and “users” configurations.
💡 We internally discussed the possibility to work-around our issue including Tugger within our chart rather than including the Tugger chart into the chart dependencies BUT the effort level was too high.
- Finally, we faced what is for us a design issue, with no workaround : the impossibility to exclude specific pods from the pods definition rewriting process (see “Rewrite image url to internal registry” within the diagram above). This functionality is mandatory, mainly for the pod holding the registry/managing its upgrade and for the “system” pods.
💡 With Tugger, the rewrite process is done through a regular expression on the images access URL. In this context, it is quite difficult to segregate the pods that SHOULD BE rewritten VS the ones that SHOULD NOT. As an example, you can not do it via a label.
💡 An option is to filter by namespace (or define a “whitelist”), BUT this is not enough and does not give us the room / granularity we need.
💡 Finally, this regular expression creation process is done through a single configuration file, and needs to be deployed each time a change is made. This way of working complicates the tool use & its integration into a wider context.
All those combined items push us to rollback our plan (complicated installation, extra work, dependencies to other projects, sub optimal configurations).
We finally moved to our own Kubernetes-native caching solution : kuik!
Introducing kube-image-keeper: A Kubernetes-Native Image Cache
We finally decided to replace the previous combination by the Docker registry distribution, easier to install than Harbor, and a k8s operator, developed on our own.
The operator is broken down into 3 main components :
- A mutating webhook, rewriting on-the-fly the pods definitions, updating the registry it uses.
- A first controller, examining pods and creating “CachedImages” custom resources accordingly.
- Another controller, watching the “CachedImages” & taking care of pulling to the cache the relevant images.
For the sake of completeness :
On top of the registry & the operator, we also put in place a proxy in front of the registry. Thus, when kubelet asks the CRI to pull pods images, the proxy will transfer the request to the upstream registry, including the authentication, in conditions in which the images are not yet available in the cache.
Final project architecture
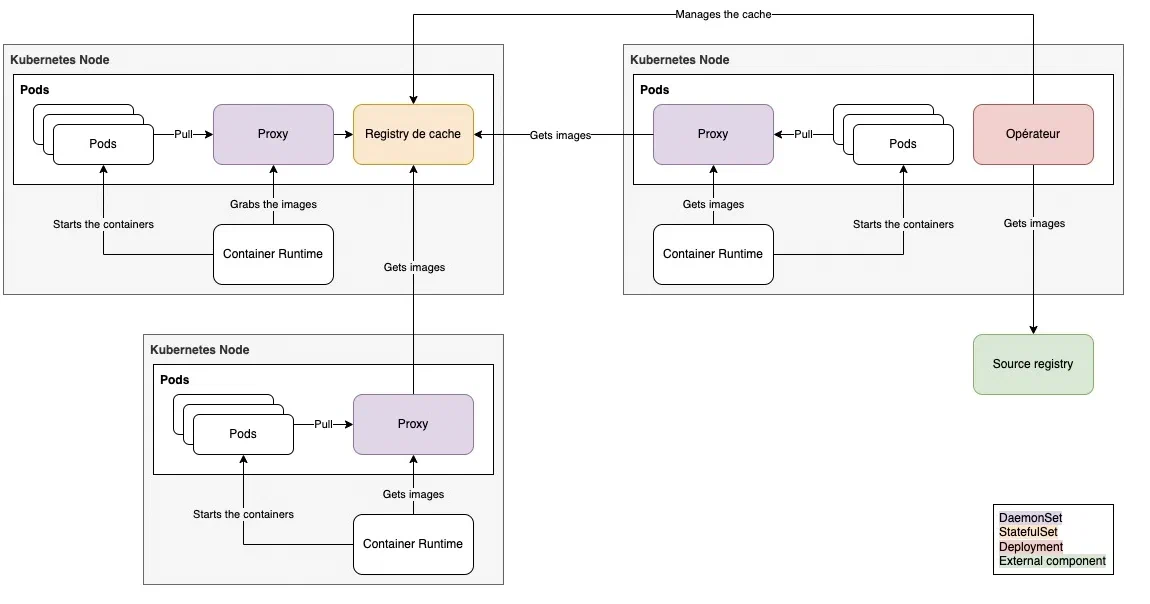 The architecture design for our kubernetes k8s image local caching/proxy solution!
The architecture design for our kubernetes k8s image local caching/proxy solution!
A couple of details
- The proxy can be launched on the control-plane.
- This setup is a “standard one” for “infrastructure components”, such as logging agents or metrology. It was thus a MUST HAVE for “our” proxy.
- The proxy is deployed through a daemonset. The CRI does not have access to the kubernetes service discovery and is thus not “services aware”. 2 solutions in order to get it access the proxy :
- Through an ingress
- Through localhost, with a daemonset.
- With the 1st solution, the registry is publicly available. This is something we wanted to avoid, at least in the very beginning. We thus used the 2nd solution.
Typical scenario for container image retrieval
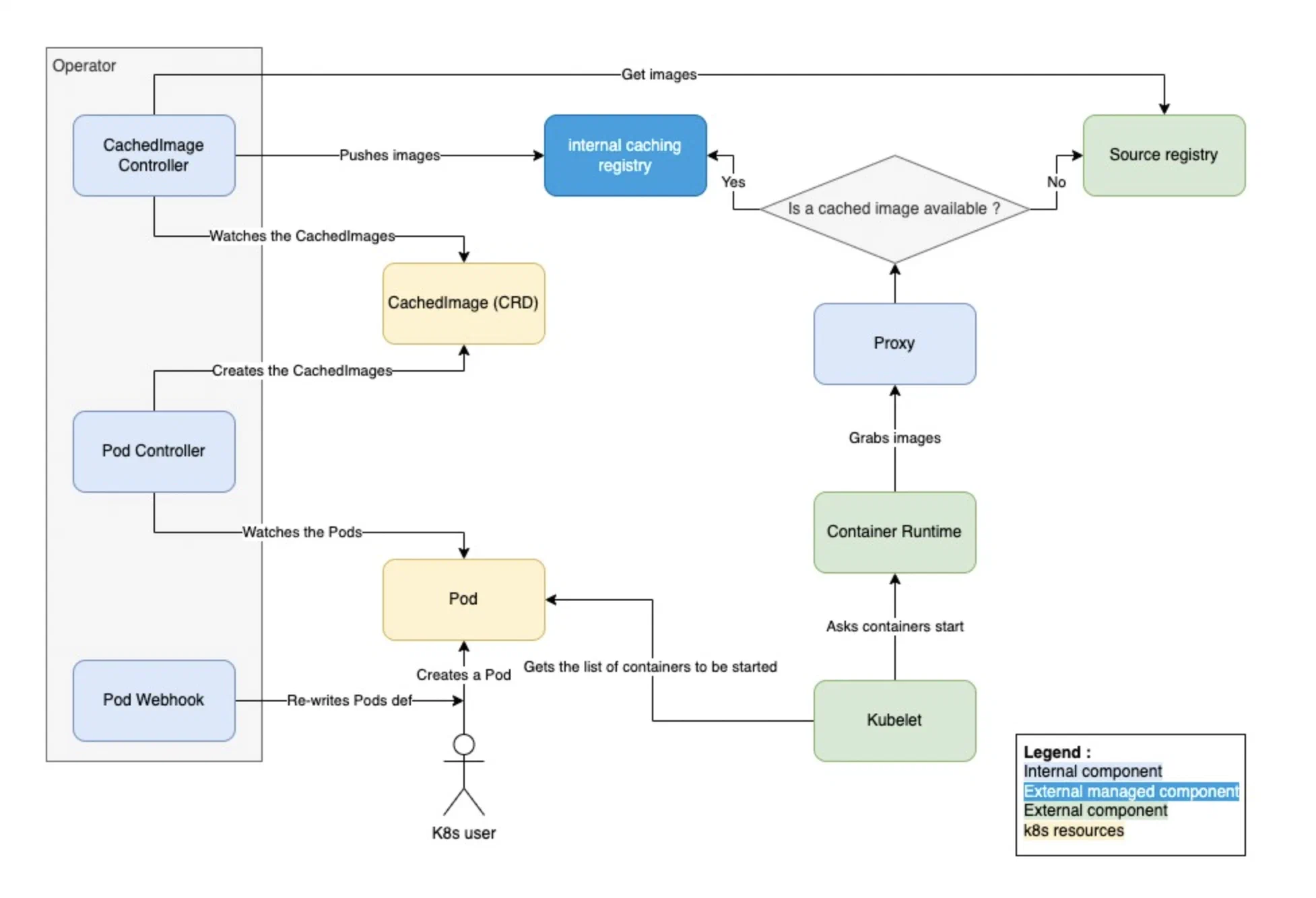
Once the missing component was developed & integrated, we finally got what we were waiting for : kube-image-keeper “production/OPS ready”!
As a matter of fact :
- We now control the pods on which the cache mechanism is used, and on top of if the ones in which this mechanism MUSTN’T apply (registry, control-plane components)
- We manage the cache lifecycle, and can interact with it (cache images follow-up, partial/full removal, garbage-collecting …)
- The tool is compatible with the vast majority of images (versioning, formalism, registries …). We did not want to put in place a docker image cache.
- This component is an enabler for Day 0, Day 1 and Day 2 operations and does not add extra risks in production environment :
- A kubernetes cluster using it remains “OPS compatible”, even though the tool goes down
- The tool becomes “transparent” in case the used images can not be set in cache for some reason.
- It can be easily updated, and the cached images are kept in the context of an upgrade.
- Finally, the tool is not hardly linked to a specific source registry, and is compatible with all the ecosystem registries (given by the Cloud Providers, CI/CD solutions, Quay, Docker …)
Using kube-image-keeper in Production
- The tool has been tested and validated with K8s clusters up to 1.31 release
- If you plan to use kube-image-keeper in production, we strongly recommend that you put in place a persistent storage solution!
💡 Some cases you can face :
● The proxy, deployed through a DaemonSet, can be reached by the CRI through localhost, using the hostPort configuration within the proxy containers. This feature allows to “publish” a port from the host and requires, when used with kube-router, the use for the plugin portmap.
● As of today, there is no way to manage container images based on a digest rather than a tag. The rational behind this limitation is that a digest is an image manifest hash, containing itself the registry URL associated with the image. Thus, caching the image changes its digest and as a consequence, once the image is set in cache, it is not anymore referenced by its original digest. We would need to rewrite the container image. This is not feasible with the current design.
Tips & tricks
- Let’s say you already have a couple of k8s clusters and want to benefit from kube-image-keeper features on it : kuik, after its install will proactivaly cache the already used images !
- During the installation or at any stage, as a kube-image-keeper admin, you can cache, in advance, images you’ll need in the future. And you can do the same with Helm charts !
- Finally, we also fine-tuned kuik so that you can use it on a convenient way within Cloud Providers environments
Future Roadmap for kube-image-keeper
We plan to continuously improve kube-image-keeper, for example with:
- Adding new blocks to the tool (security, events notifications …) ;
- Increasing the test code coverage with automation ;
Try kube-image-keeper Today!
We’re excited to share kube-image-keeper with the Kubernetes and Open Source community! 🚀
🔗 Get started with kube-image-keeper: enix/kube-image-keeper.
If you have any questions, feedback, or contributions, we’d love to hear from you! Try out kube-image-keeper and let us know your thoughts. :) Also, we’re actively working on a v2, stay tuned !
Do not miss our latest DevOps and Cloud Native blogposts! Follow Enix on Linkedin!