
Génèse du projet
Chez Enix, nous gérons des centaines de clusters Kubernetes pour nos clients ainsi que pour nos propres besoins internes. Lors d’opérations quotidiennes de clusters Kubernetes de production, il nous est arrivé de rencontrer des problèmes liés à la récupération d’images de conteneurs. Et l’un de nos défis récurrents est d’assurer un caching des images Kubernetes de façon fiable.
Un exemple assez commun est celui de l’indisponibilité d’une registry d’images.
Histoire vraie : On souhaite mettre à jour un cluster Kubernetes pour palier à un problème de sécurité, corriger un bug ou “rollback” vers une version plus stable suite à une mise à jour en défaut. Et là, surprise:
On apprend un peu par hasard (et tardivement) que la registry publique d’images de conteneurs est indisponible, ce qui oblige … à retarder la correction et à prendre son mal en patience.
Même punition lorsque l’on atteint son quota de pull sur des registry telles que le Docker Hub ou Quay (dans une moindre mesure).
Après quelques occurrences de ce problème, et parce que c’est dans l’ADN Enix, nous décidons de mettre en place une solution de caching d’images de conteneurs (Docker, et OCI plus globalement) au sein même d’un cluster Kubernetes.
Sans dévoiler la fin du “film”, nous parlerons proxy, registry, CRD, opérateur kubernetes …
Le projet kube-image-keeper est né !
Sans rentrer dans un listing complet, les problèmes auxquels cet outil doit répondre sont les suivants :
- L’indisponibilité de registry publiques d’images de conteneurs.
- Les limites de pull imposées par certaines de ces registry, notamment dans leur déclinaisons gratuites.
- L’indisponibilité d’une image à un instant T.
- Les politiques de gestion de l’espace disque dans un contexte CI/CD peuvent amener à ce qu’une image toujours utilisée par un cluster Kubernetes ait été supprimée de la registry pour faire place à des images plus récentes.
Nous développons cet outil également pour satisfaire les différents profils utilisateurs. Celui-ci doit permettre de :
- Satisfaire particulièrement les OPS ou les sociétés d’infogérance cloud en charge d’infrastructures kubernetes on premise, en positionnant ce nouveau composant au plus près de leur infrastructure / en limitant les appels à l’extérieur
- Dans un contexte plus large, grâce au caching local des images, d’optimiser les temps de déploiement des applications.
Évaluation des solutions existantes de mise en cache d’images Kubernetes
Le démarrage de ce projet, début 2022, est marqué par les 1ers choix d’architecture de proxy et de caching des images au sein de la plateforme Kubernetes.
Dès le début, notre volonté principale est de réutiliser autant que possible des composants déjà existants.
Plusieurs outils “du moment” semblent répondre à tout ou partie du besoin, de façon autonome ou combinée et retiennent notre attention:
Démarrage à la machette : on défriche kubernetes-image-puller !
kubernetes-image-puller est écarté après une lecture fine de la documentation, avant même le moindre test, principalement car l’outil ne supporte selon nous qu’une partie trop limitée des images.
💡 Les images ayant vocation à être fréquemment utilisées par le cluster k8s doivent être récupérées et lancées une première fois avec la commande sleep 720h (si absente, les images sont bien téléchargées MAIS le container bascule tout de suite en CrashLoopBackOff …), pour initialiser des pods “témoins”, avant de pouvoir être cachées localement et utilisées pour les usages suivants.
💡 Ce problème a un peu évolué depuis nos tests, mais le résultat obtenu ne nous paraît toujours pas suffisant !
💡 kubernetes-image-puller déploie par ailleurs un nombre faramineux de containers sur le cluster (un container par image et par node / utilisation d’un daemonset pour la mise en cache), uniquement pour la fonction de cache. Avec 5 nœuds et 10 images à cacher, on arrive déjà à 50 containers qui “dorment”…
Du “clés en main” avec kube-fledged ?
Nous démarrons alors nos tests de kube-fledged, qui nous semble être plus proche de ce que nous souhaitons faire.
Cet outil permet de cacher une liste d’images définies à la main via un ensemble de CRDs. Cette implémentation nous parait une bonne base pour construire autour ce qui est manquant : la détection automatique des images à cacher, que nous imaginons déléguer à du code customisé, lequel ira mettre à jour les CRDs.
Malheureusement, nous sommes vite arrêtés dans notre élan car cet outil ne limite pas les appels à la registry source (bien au contraire!), et il entraîne une surconsommation de stockage local sur les nœuds.
Nous sentons que nous n’atteindrons pas nos objectifs sans embarquer une registry locale, se sourçant le moins possible sur les registry sources !
Tugger en harmonie avec Harbor ?
Cette expérience décevante nous pousse à affiner notre besoin technique et à nous tourner vers d’autres solutions. Nous décidons alors d’utiliser la combinaison Harbor (cache/registry) + Tugger (moteur).
Ci-dessous, le schéma d’architecture associé à cette 2nde itération :
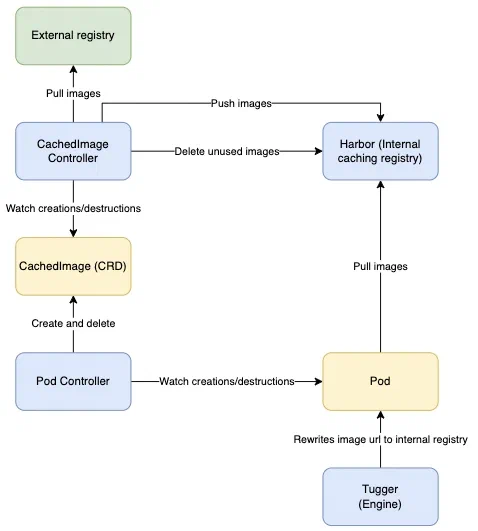
Nous touchons au but, mais :
- Installer Harbor, déjà riche en features et donc relativement lourd à l’installation, la configuration etc … pour l’utiliser uniquement comme cache ne nous paraît pas pertinent.
- Tugger présentait un problème au niveau de la séparation des rôles, le rendant incompatible avec notre besoin.
💡 Tugger possède un unique fichier de configuration, défini via les values de son Helm chart, ce qui ne nous permet pas d’intégrer de configurations “système” (telles que l’exclusion de la mise en cache des images de l’outil) en plus des configurations utilisateur.
💡 Nous aurions pu contourner cela en incluant Tugger directement dans notre chart plutôt que d’inclure le chart Tugger dans les dépendances du chart. Cela représentait cependant un volume d’efforts trop important pour un apport limité.
- Enfin, nous nous sommes heurtés à ce qui constitue pour nous un problème de conception, pour lequel nous n’avons pas trouvé de solution : Avec Tugger, il est impossible, d’exclure sereinement certains pods du processus de réécriture (cf. la fonction “Rewrite image url to internal registry” dans le schéma ci-dessus).. Cette fonctionnalité est pourtant indispensable, notamment pour le pod portant la registry, et gérer son upgrade, ainsi que pour les pods “système” !
💡 Avec Tugger, les réécritures évoquées sont effectuées via une expression régulière sur les url d’accès aux images. Il est dans ce contexte très difficile de “faire le tri” entre les pods à réécrire et ceux à NE PAS réécrire.
💡 Il est impossible de filtrer les pods via un label. Il est par contre possible de filtrer par namespace (ou du moins d’en définir une “whitelist”), mais cela n’est pas suffisant et ne permet pas de travailler avec la granularité que nous recherchions.
💡 Enfin, la mise en place de ces expressions régulières est faite via un unique fichier de configuration qui demande un redéploiement systématique à chaque changement, ce qui ne facilite pas l’utilisation de l’outil et son intégration dans un contexte plus large.
L’ensemble de ces points rendent l’utilisation de Harbor combiné à Tugger sujette à trop de complications (installation compliquée, travail supplémentaire à fournir, dépendance à des projets, packages sur lesquels nous n’avons pas la main, configuration non-optimale pour nos besoins, etc). Nous sommes donc partis sur notre propre solution : kuik !
kuik, notre solution de caching d’image pour Kubernetes
Nous décidons de remplacer la combinaison précédente par la registry “distribution” de Docker, plus légère et plus simple à installer que Harbor, ainsi qu’un opérateur Kubernetes développé par nos soins. Celui-ci est constitué de 3 composants principaux :
- Un mutating webhook qui ré-écrit à la volée les images des pods et les fait pointer vers notre registry de cache.
- Un premier contrôleur qui observe les pods et crée des custom resources “CachedImage” en conséquence.
- Un second contrôleur qui observe les CachedImage et s’occupe de mettre en cache les images correspondantes.
Pour être complet : En complément de la registry et de l’opérateur, nous avons également mis en place un proxy devant la registry. Ainsi, lorsque kubelet demande à la CRI de pull les images d’un pod, le proxy réorientera les requêtes vers la registry d’origine, authentification incluse, si celles-ci ne sont pas encore disponibles dans le cache.
Architecture finale de l’outil
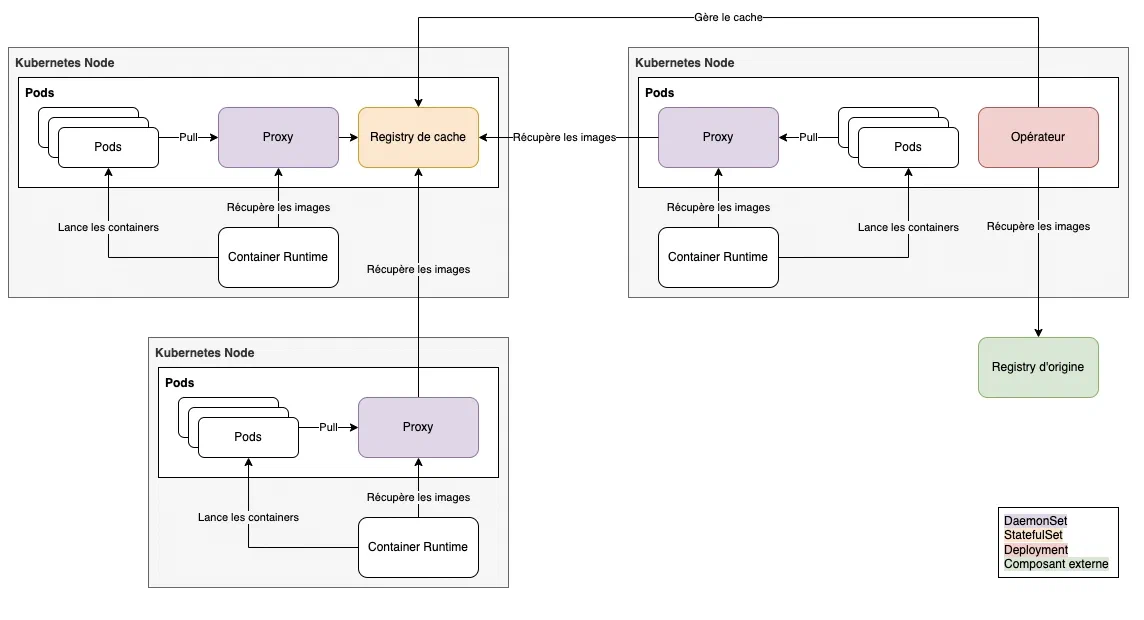
Détails d’implémentation
- Le proxy peut être lancé sur le control-plane.
- Il est courant d’avoir certains composants d’infrastructure déployés sur le control-plane, comme des agents de logging ou de métrologie. Notre proxy se devait donc d’être disponible sur les nodes du control-plane.
- Le proxy est déployé via un daemonset. En effet, la CRI n’a pas accès au service discovery de Kubernetes, il n’est donc pas conscient des services. Il existe 2 solutions pour lui permettre d’accéder aux proxy : via une ingress ou via localhost en déployant avec un daemonset. Le problème de l’ingress est que le registry se retrouve accessible publiquement, ce que nous voulons éviter. C’est donc l’option du daemonset qui a été retenue.
Cas typique de récupération d’une image
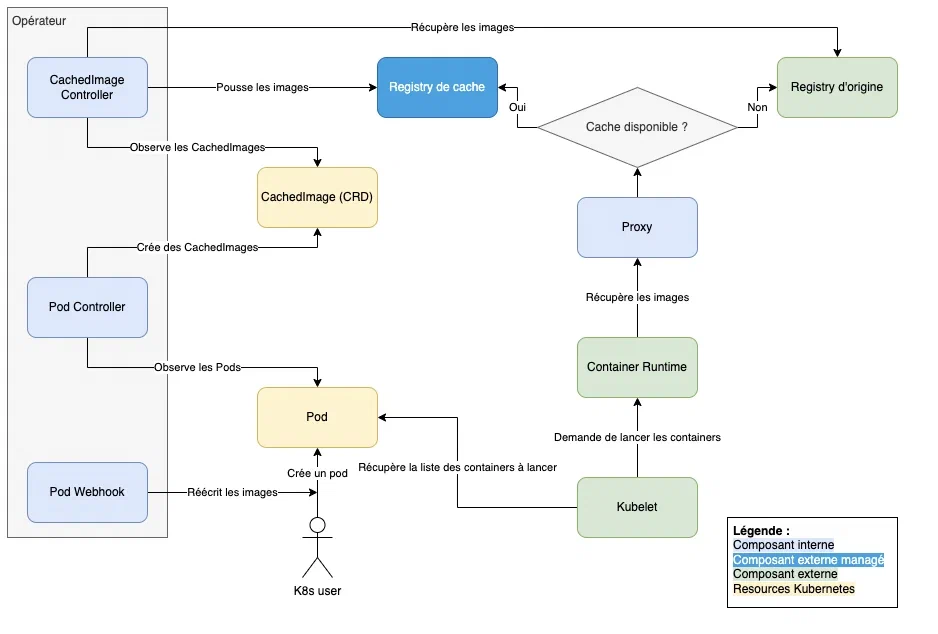
Une fois le composant manquant développé, et le tout intégré, nous aboutissons à un nouvel outil qui répond à nos besoins et utilisable en opérations : kube-image-keeper !
En effet :
- Nous maîtrisons les pods sur lesquels le mécanisme de cache d’image est utilisé, et surtout ceux sur lesquels celui-ci ne DOIT PAS s’appliquer (registry, composants du contrôle-plane)
- Nous gérons le cycle de vie du cache, et pouvons agir dessus (suivi des images en cache, suppression partielle ou complète des images de celui-ci, garbage-collecting etc …)
- Compatibilité avec l’écrasante majorité des images Docker ou plus globalement OCI (versioning, formalisme, registry …)
- Ce composant est un facilitateur d’opérations Day 0, Day 1, Day 2 et n’introduit pas de risque supplémentaire en production : :
- Un cluster qui l’utilise reste toujours opérable, même si celui-ci venait à tomber.
- Il devient “transparent” si les images utilisées ne peuvent pas être mises en cache, pour une raison ou pour une autre.
- Il peut être mis à jour simplement, et les images en cache sont bien sauvegardées après upgrade.
- Enfin, l’outil ne dépend pas d’une registry source particulière, il est bien compatible avec toutes les registry de l’écosystème (fournies par les Cloud Provider, les solutions de CI/CD, Quay, Docker …)
Utiliser kube-image-keeper en production
- L’outil a été testé et validé avec des clusters K8s jusqu’à la version 1.31.
- Si vous envisagez un usage en production de kube-image-keeper, nous recommandons très fortement de mettre en place un stockage persistant !
💡 Quelques situations que vous pouvez rencontrer dans certains cas précis d’utilisation de kuik :
● Les proxies déployés en daemonset sont atteints par la CRI directement en localhost. Pour cela on utilise la configuration hostPort dans les containers du proxy. Cette fonctionnalité qui permet de publier un port directement sur la machine hôte requiert, dans le cadre de l’utilisation de kube-router, l’utilisation du plugin portmap.
● Pour l’instant, il n’est pas possible de gérer les images basées sur un digest au lieu d’un tag. La raison est qu’un digest est un hash du manifeste d’une image, qui lui-même contient l’url de la registry où se trouve l’image. Mettre en cache l’image change donc son digest, si bien qu’une fois l’image mise en cache, elle n’est plus référencée par son digest d’origine. Il faudrait donc réécrire à nouveau l’image après l’avoir mise en cache, ce qui n’est pas possible avec le design actuel.
Trucs & astuces
- Vous pouvez utiliser kuik et ses fonctionnalités sur un cluster k8s déjà utilisé : après son installation, kuik détectera les images déjà utilisées et, ira proactivement les cacher !
- Que ce soit pendant l’installation ou à n’importe quel moment, en tant qu’administrateur kuik, vous pourrez demander une mise en cache, “en avance”, d’images dont vous aurez besoin dans le futur.
- Enfin, nous avons aussi travaillé à faciliter l’utilisabilité de kuik dans les environnements Cloud Provider.
Roadmap de kube-image-keeper
Depuis sa création, kube-image-keeper embarque régulièrement de nouvelles fonctionnalités et nous prévoyons d’améliorer continuellement, par exemple en :
- Ajoutant de nouveaux modules à l’outil (sécurité, notifications d’événements…) ;
- Augmentant la couverture des tests par automatisation ;
Essayez kube-image-keeper dès aujourd’hui !
Nous sommes ravis de partager kube-image-keeper avec la communauté Kubernetes et Open Source ! 🚀
kuik a été présenté à la communauté lors de KCD France 2023 qui a accueilli près de 1000 personnes et qu’Enix a contribué à organiser.
🔗 Commencez dès maintenant à l’utiliser : enix/kube-image-keeper
Si vous avez des questions, des retours ou des contributions, nous serions ravis d’échanger avec vous ! 😊
Ne ratez pas nos prochains articles DevOps et Cloud Native! Suivez Enix sur Linkedin!