
Cet article est le dernier d’une série de 3 sur le monitoring avec un focus sur Thanos.
- Partie 1 : “Thanos : stockage des métriques Prometheus sur le long terme”
- Partie 2 : “Déployer Thanos et Prometheus sur un cluster K8s”
- Partie 3 : “Thanos : agrégation de plusieurs Prometheus”
Dans le précédent article de cette série sur Thanos, nous nous étions arrêtés sur la configuration du Thanos Query comme datasource sur Grafana pour pouvoir interroger plusieurs instances Prometheus depuis la même datasource.
Passons maintenant à l’utilisation de Thanos pour agréger plusieurs instances Prometheus. Nous allons aborder deux cas utiles : au sein d’un même cluster Kubernetes, puis dans plusieurs clusters.
Thanos et plusieurs instances Prometheus dans un même cluster K8s
Présentation du cas
On va prendre l’exemple d’un cluster kubernetes avec plusieurs namespaces, utilisé par des équipes différentes. Chaque équipe a son Prometheus qui récupère leur métriques et il y a un Prometheus système qui récupère les métriques du cluster en lui-même.
Le but est d’avoir toutes nos métriques accessibles sur Grafana, peu importe le Prometheus qui possède la métrique. Voyons comment configurer nos Prometheis (le savais-tu, le pluriel de Prometheus, c’est Prometheis) et Thanos pour mettre ça en place. Par simplicité dans cet article, on ne va pas configurer le stockage long terme des métriques avec Thanos, mais uniquement la vue globale.
Déployer les Prometheis avec le Thanos sidecar
Pour le Prometheus système, on va simplement utiliser le chart kube-prometheus-stack comme on l’a fait dans l’article “Superviser Kubernetes avec Prometheus”. On configure le Prometheus pour ne cibler que les PodMonitor et ServiceMonitor qui ont un label prometheus. De cette manière, on différencie ce qui doit être supervisé par le Prometheus système et ce qui doit être supervisé par d’autres instances.
prometheus:
prometheusSpec:
serviceMonitorSelector:
matchExpressions:
- key: prometheus
operator: DoesNotExist
podMonitorSelector:
matchExpressions:
- key: prometheus
operator: DoesNotExist
thanos:
version: 0.31.0
On crée une instance Prometheus par équipe qui va uniquement cibler les PodMonitor et ServiceMonitor qui possèdent un label prometheus avec le nom de l’équipe:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: team1
namespace: monitoring
spec:
serviceMonitorSelector:
matchLabels:
prometheus: team1
podMonitorSelector:
matchLabels:
prometheus: team1
thanos:
version: 0.31.0
serviceAccountName: kube-prometheus-stack-prometheus
Et pour tester le tout, on va rajouter un PodMonitor qui récupère les métriques du Prometheus:
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
labels:
prometheus: team1
name: prom-team1
namespace: monitoring
spec:
jobLabel: app.kubernetes.io/name
podMetricsEndpoints:
- path: /metrics
port: web
selector:
matchLabels:
operator.prometheus.io/name: team1
Configurer le Thanos Query pour cibler les sidecars
On va déployer Thanos avec le chart bitnami/thanos comme dans le précédent billet. Nos instances Prometheus sont déployées par l’opérateur, donc elles sont joignables via le service prometheus-operated ajouté automatiquement. On peut utiliser le DNS Service Discovery de Thanos pour cibler tous nos Prometheus d’un coup avec les valeurs suivantes:
query:
dnsDiscovery:
sidecarsService: "prometheus-operated"
sidecarsNamespace: "monitoring"
Vérifier le résultat sur la WebUI
Si l’on se connecte sur le Thanos Query, dans l’onglet “Stores” on a bien nos différents Thanos sidecar:
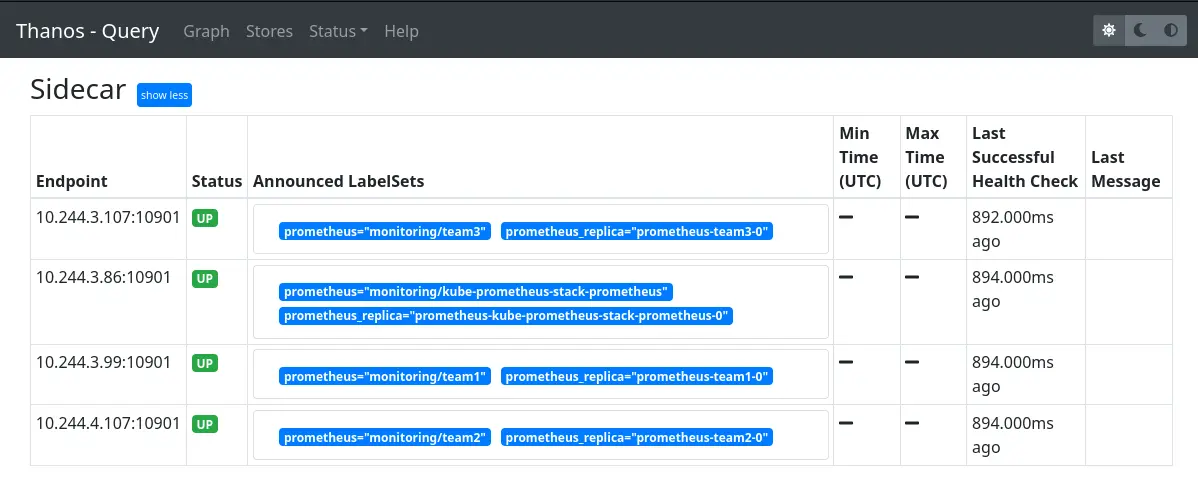
Et l’on peut tester une requête pour vérifier que tous les Prometheis sont bien interrogés :
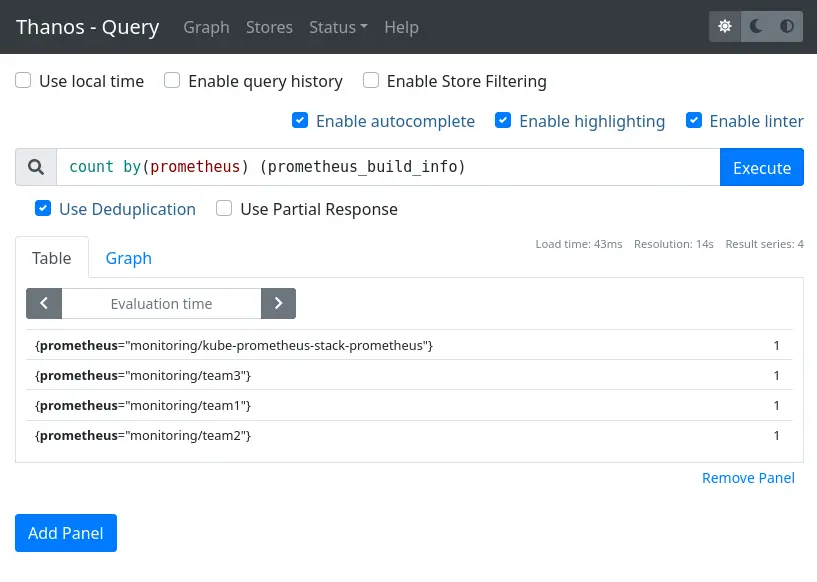
Il ne reste plus qu’à rajouter le Thanos Query comme datasource de type Prometheus côté Grafana pour l’utiliser.
Thanos et plusieurs clusters K8s supervisés par Prometheus
Présentation du cas
Maintenant, au lieu de vouloir une vue globale sur des Prometheus au sein d’un même cluster, on veut cibler différents clusters Kubernetes. Il faut que notre Thanos Query puisse joindre la StoreAPI Thanos des autres clusters. La StoreAPI est exposée en gRPC, qui lui même utilise HTTP/2 comme transport, donc on peut utiliser un Ingress pour simplifier. Dans notre exemple on va utiliser ingress-nginx comme ingress controller.
Déployer Prometheus et le Thanos sidecar exposé via un ingress
On installe Prometheus avec le chart kube-prometheus-stack, avec les valeurs suivantes :
prometheus:
prometheusSpec:
externalLabels:
cluster: cluster-b
thanos:
version: 0.31.0
thanosIngress:
enabled: true
ingressClassName: nginx
annotations:
nginx.ingress.kubernetes.io/backend-protocol: "GRPC"
cert-manager.io/cluster-issuer: letsencrypt
hosts:
- thanos-grpc.cluster-b.example.com
pathType: Prefix
tls:
- secretName: thanos-sidecar-tls
hosts:
- thanos-grpc.cluster-b.example.com
Deux points important ici :
- On met un external label avec le nom du cluster, ça va permettre d’utiliser les dashboards Grafana Kubernetes en mode multi-cluster,
- On utilise l’annotation
nginx.ingress.kubernetes.io/backend-protocolen modeGRPCpour que l’ingress-nginx parle en gRPC au service
Configurer Thanos Query pour récupérer les métriques de tous les clusters
On déploie Thanos avec les valeurs suivante pour lui indiquer de joindre les deux sidecars exposés via un ingress en HTTPS:
query:
stores:
- 'thanos-grpc.cluster-b.example.com:443'
- 'thanos-grpc.cluster-c.example.com:443'
extraFlags:
- --grpc-client-tls-secure
queryFrontend:
enabled: false
Quand on regarde l’interface web de Thanos Query, on voit bien nos deux sidecars :
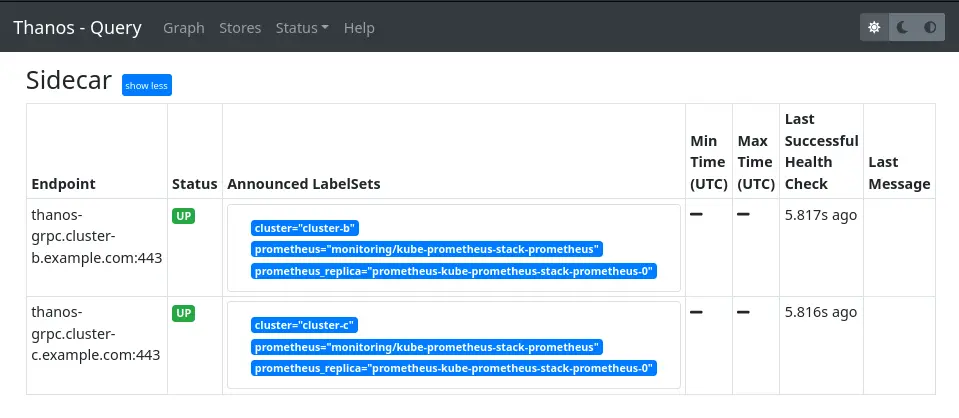
On veut aussi ajouter les sidecars de notre premier cluster pour être complet. Le problème c’est que l’on utilise l’option --grpc-client-tls-secure et que nos premiers sidecars n’utilisent pas de TLS, donc ça ne va pas fonctionner. Il y a une issue ouverte à ce sujet, en attendant que ce soit implémenté on peut utiliser le Thanos Query que l’on vient de créer comme intermédiaire et le rajouter dans la configuration du Thanos Query que l’on avait configuré précédemment :
query:
dnsDiscovery:
sidecarsService: "prometheus-operated"
sidecarsNamespace: "monitoring"
stores:
- 'dnssrv+_grpc._tcp.thanos-external-query-grpc.monitoring.svc.cluster.local'
Le Thanos Query expose également la StoreAPI, il est donc possible d’en cibler au même titre qu’on cible un sidecar ou une storegateway. Ici on utilise toujours le DNS Service Discovery pour pointer sur le service de notre autre instance Thanos Query.
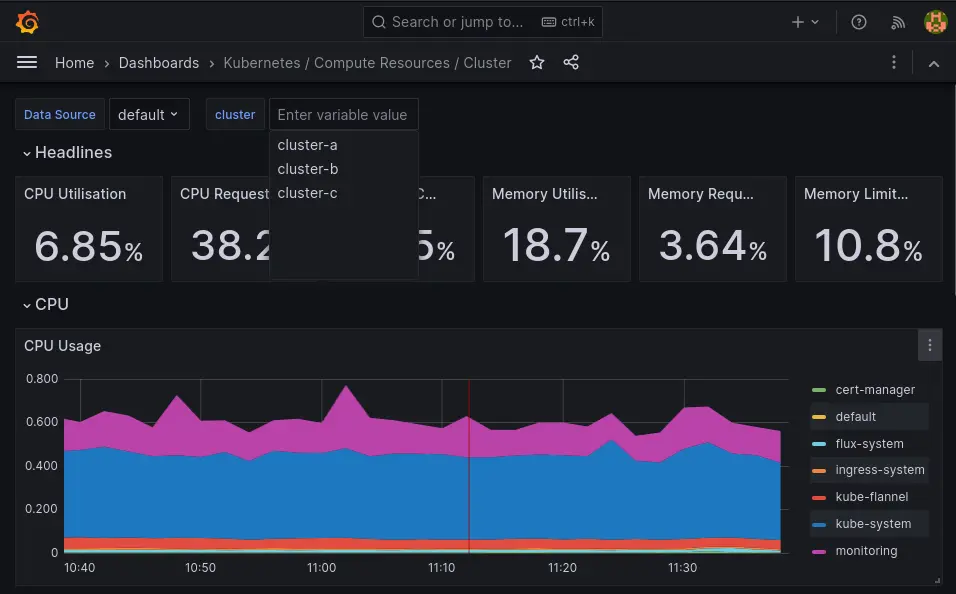
On ajoute un external label cluster sur les Prometheis déployés dans la première partie comme on vient de le faire pour les nouveaux clusters. Maintenant, sur l’interface du Thanos Query on voit bien toutes nos instances :
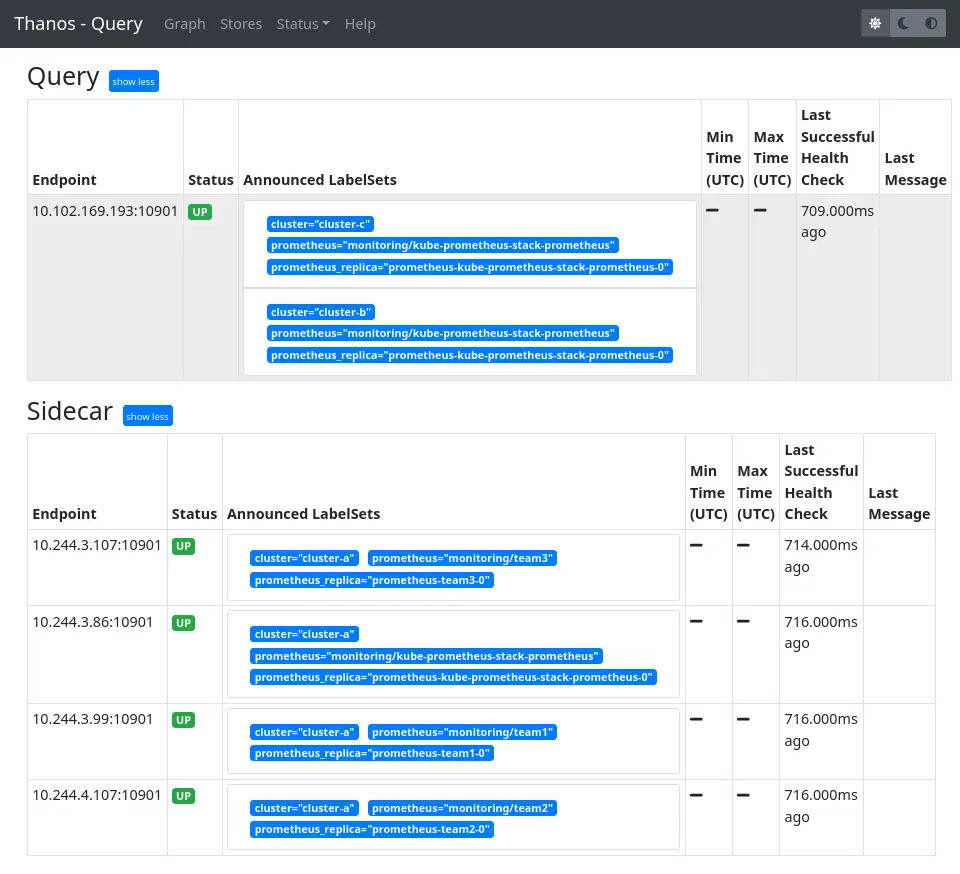
Configurer les dashboard Kubernetes multi-cluster et vérifier le résultat sur Grafana
Il ne reste plus qu’à configurer les dashboards Kubernetes déployés par le chart kube-prometheus-stack pour être multi-cluster avec les valeurs suivantes :
grafana:
enabled: true
sidecar:
dashboards:
multicluster:
global:
enabled: true
etcd:
enabled: true
On redéploie le chart puis on ajoute Thanos comme datasource Grafana :
Et il ne reste plus qu’à parcourir les dashboards Kubernetes qui ont désormais un filtre cluster pour pouvoir visualiser les métriques de toutes nos instances à partir de la même datasource.
Voilà qui conclut cette série de trois articles découverte de Thanos. On se retrouve bientôt pour de nouveaux sujets de supervision !
Ne ratez pas nos prochains articles DevOps et Cloud Native! Suivez Enix sur Linkedin!