
Cet article est le premier d’une série d’articles consacrée à l’utilisation de Prometheus.
Surveiller ses applications et son infrastructure est essentiel quand on opère une plateforme : pour être informé lorsqu’un problème survient ou mieux encore, pour l’anticiper. Kubernetes ne fait pas exception à la règle et nous allons voir ici en quoi Prometheus est le compagnon idéal pour superviser Kubernetes.
Les métriques dans Kubernetes
Dans un cluster Kubernetes, beaucoup d’éléments peuvent remonter des métriques utiles pour la supervision, faisons un tour d’horizon.
Les pods
C’est souvent les métriques qui intéressent le plus les utilisateurs, celles exposées directement par notre application (via une page dédiée ou un exporter en sidecar par exemple).
Mais il y a aussi les ressources utilisées par les conteneurs, principalement l’utilisation CPU et RAM, qui sont remontées par le Kubelet.
Les ressources Kubernetes
Les deployments, statefulset, job, secret, … On retrouve des métriques pour une bonne partie des ressources Kubernetes (via l’exporter kube-state-metrics). Il y a des métriques très génériques communes aux différentes ressources, mais aussi des métriques plus précises en rapport avec la ressource en question. Par exemple, on peut avoir le nombre de restart d’un container au sein d’un pod, l’état des replicas d’un deployment ou encore les status d’un job.
Le control-plane
L’API Server, controller-manager, le scheduler ou encore l’etcd. Ces composants du control-plane Kubernetes remontent chacun de nombreuses métriques très utiles pour détecter des problèmes sur notre cluster.
Les nodes
On a évidemment le classique node-exporter qui va remonter l’état de la machine, mais il faut également ajouter les métriques de Kubelet, ainsi que les certificats utilisés par les composants de Kubernetes.
Les composants système
Et l’on n’oublie pas les métriques des composants de base comme celui qui vous fournit le réseau (CNI) ou le stockage persistant (CSI), l’ingress-controller, celui de Gitops, … et bien évidemment Prometheus lui-même.
Prometheus à la sauce Kubernetes
On vient de le voir, il y a un certain nombre de choses à récupérer par notre Prometheus. Heureusement, il existe des projets pour nous aider dans notre périlleuse mission.
prometheus-operator
Le prometheus-operator a pour rôle de gérer Prometheus (spawner les pods, maintenir la redondance, …) ainsi que de générer ses différentes configurations (targets, alertes, …) depuis des Custom Resources comme par les ServiceMonitor ou les PodMonitor par exemple.
Cet opérateur est devenu un indispensable dans n’importe quel cluster Kubernetes et de très nombreuses applications fournissent un ServiceMonitor (une des CustomResources qui décrit comment récupérer les métriques depuis un Service) dans leur chart Helm.
kube-prometheus
Le projet kube-prometheus fournit un ensemble de manifests, et autres éléments nécessaires pour monitorer un cluster Kubernetes :
- le prometheus-operator vu plus haut, avec une instance de la CustomResource Prometheus incluse
- l’exporter node-exporter sur chaque node du cluster
- l’exporter kube-state-metrics
- tout un ensemble de ServiceMonitor pour chacun des exporter à monitorer
Mais il fournit également de quoi exploiter ces métriques par défaut avec :
- un Grafana, pour afficher toutes les métriques récupérées sur des dashboards
- un Alertmanager, pour envoyer les alertes générées à partir des métriques
- kubernetes-mixin (cf ci-dessous)
kubernetes-mixin
Ce dernier, justement, est un projet qui regroupe de nombreux dashboards pour Grafana et alertes pour Prometheus.
Les dashboards fournis sont clairement une base très appréciable pour voir ce qui se passe dans son cluster.
kube-prometheus-stack: Un chart Helm pour les gouverner tous
Un chart Helm tout trouvé.
Un chart Helm pour les déployer tous et dans les ténèbres nous éclairer.

kube-prometheus-stack est notre meilleur allié pour sortir du noir et voir ce qui se passe sur notre cluster Kubernetes.
Il se base sur le projet kube-prometheus que nous avons vu plus haut et rend le tout facilement déployable et extrêmement configurable part un chart Helm via de très nombreuses values.
C’est LA bonne méthode pour déployer Prometheus dans Kubernetes, superviser tous les composants et avoir les outils de base pour exploiter les métriques.
Exemple sur un cluster déployé avec kubeadm
Installation
Place à la pratique, on va voir concrètement la mise en place sur un cluster déployé avec kubeadm.
On installe le chart avec :
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
kubectl create ns monitoring
helm -n monitoring install kube-prometheus-stack prometheus-community/kube-prometheus-stack
On se retrouve avec plusieurs pods dans notre namespace monitoring :
$ kubectl -n monitoring get pod -o name
pod/alertmanager-kube-prometheus-stack-alertmanager-0
pod/kube-prometheus-stack-grafana-649d6dcddc-j9dsj
pod/kube-prometheus-stack-kube-state-metrics-9d456cddd-gm94f
pod/kube-prometheus-stack-operator-66bfdc5dc8-589s2
pod/kube-prometheus-stack-prometheus-node-exporter-6zdgx
pod/kube-prometheus-stack-prometheus-node-exporter-9czwc
pod/kube-prometheus-stack-prometheus-node-exporter-9zz8f
pod/kube-prometheus-stack-prometheus-node-exporter-p5ctr
pod/kube-prometheus-stack-prometheus-node-exporter-pdpql
pod/prometheus-kube-prometheus-stack-prometheus-0
Il y a bien les composants que l’on a mentionnés plus tôt, le prometheus-operator, une instance de Prometheus, Alertmanager et Grafana, le kube-state-metrics et un node-exporter par nœud du cluster via un DaemonSet.
Et ce n’est évidemment pas tout, il y a plusieurs Services, ConfigMap et autres ressources liées au RBAC qui ont été créées. On retrouve bien sûr les ressources ServiceMonitor du prometheus-operator :
$ kubectl get -A servicemonitors -l 'release=kube-prometheus-stack' -o name
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-alertmanager
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-apiserver
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-coredns
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kube-controller-manager
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kube-etcd
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kube-proxy
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kube-scheduler
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kube-state-metrics
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kubelet
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-operator
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-prometheus
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-prometheus-node-exporter
C’est ce qui va générer les ’targets’ côté Prometheus. Et justement vérifions cela, on va faire un port-forward sur le Prometheus pour voir ce qu’il récupère :
kubectl -n monitoring port-forward prometheus-kube-prometheus-stack-prometheus-0 9090:9090
On ouvre un navigateur sur http://localhost:9090 et on va dans Status/Targets :

On y retrouve bien les ressources vues plus haut. En revanche, les éléments du control-plane ne semblent a priori pas accessibles.

Si on déplie l’une des cibles on obtient :

Le cas kubeadm
La connexion est refusée, Prometheus n’arrive donc pas à récupérer les métriques. Dans ce cas, c’est parce que kubeadm a fait le choix de laisser les composants du control-plane uniquement en écoute sur localhost, ce qui ne permet pas à Prometheus de récupérer les métriques.
Une des solutions possibles est de modifier ça pour écouter plus largement, comme suggéré dans la documentation de kube-prometheus.
On va donc éditer la configuration kubeadm et reconfigurer les composants du control-plane pour prendre en compte ces modifications. On édite la configuration avec kubectl -n kube-system edit cm kubeadm-config et on ajoute l’option bind-address pour le controller-manager et le scheduler et listen-metrics-urls pour etcd :
controllerManager:
extraArgs:
bind-address: "0.0.0.0"
scheduler:
extraArgs:
bind-address: "0.0.0.0"
etcd:
local:
extraArgs:
listen-metrics-urls: http://0.0.0.0:2381
Puis sur chaque nœud du control-plane, on va faire :
kubeadm upgrade node phase control-plane
On attend bien sûr que la modification soit complètement appliquée à un nœud avant de passer au suivant, pour ne pas faire d’interruption.
Maintenant si on regarde côté Prometheus :

Le controller-manager, le scheduler et etcd sont maintenant up, mais il reste kube-proxy qui est dans la même situation avec un “connection refused”.
Le problème est similaire, par défaut il n’écoute que sur localhost, donc on va modifier ça dans la configuration avec kubectl -n kube-system edit cm kube-proxy et rajouter dans la clé config.conf :
metricsBindAddress: 0.0.0.0
Et re-deployer les pods avec:
kubectl -n kube-system rollout restart daemonset kube-proxy
On vérifie dans Prometheus et tout est up :

On peut également regarder dans le menu “Alerts” de Prometheus et on y retrouve tout un jeu d’alertes préconfigurées qui nous préviendront en cas de problème sur notre cluster.
L’accès au Grafana
Et si on regardait les dashboards que nous a installé le chart ? On va, comme pour Prometheus, faire un port-forward :
kubectl -n monitoring port-forward deployment/kube-prometheus-stack-grafana 3000:3000
Et se connecter sur http://localhost:3000
Il nous faut le mot de passe de l’utilisateur admin, par défaut le chart met prom-operator.
Une fois loggué, on peut parcourir les dashboards et voir qu’il y en a une certaine quantité qui viennent entre autres du projet kubernetes-mixin, mais pas que.
 .
.

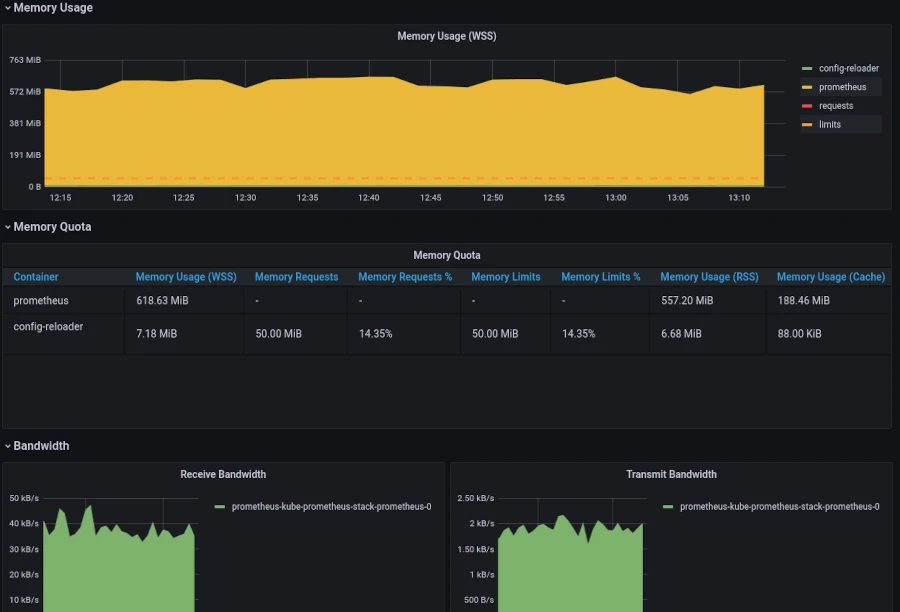
On peut regarder par exemple le dashboard “Kubernetes / Compute Resources / Pod” et voir la consommation de notre Prometheus :
 .
.
Recevoir les alertes
On a les métriques, des alertes et des dashboards. Par contre, il faut configurer un minimum Alertmanager pour lui dire où envoyer les alertes, sinon elles vont être moins utiles.
Par exemple, pour déclencher un webhook dès qu’une alerte est envoyée à Alertmanager, on rajoute dans les values du chart et on upgrade :
alertmanager:
config:
route:
receiver: 'trigger_ops'
receivers:
- name: 'null'
- name: 'trigger_ops'
webhook_configs:
- send_resolved: true
url: 'https://my-webhook-endpoint.example.com'
On ajoute un receiver par défaut nommé “trigger_ops” et on le configure avec un webhook. Ici on laisse le receiver “null” qui vient de la configuration par défaut du chart.
Bien entendu, il faut adapter en fonction des besoins en se basant sur la documentation de configuration d’Alertmanager.
Il n’y a plus qu’à tester ça, par exemple en éteignant l’une des machines du control-plane et en attendant que les alertes se déclenchent.
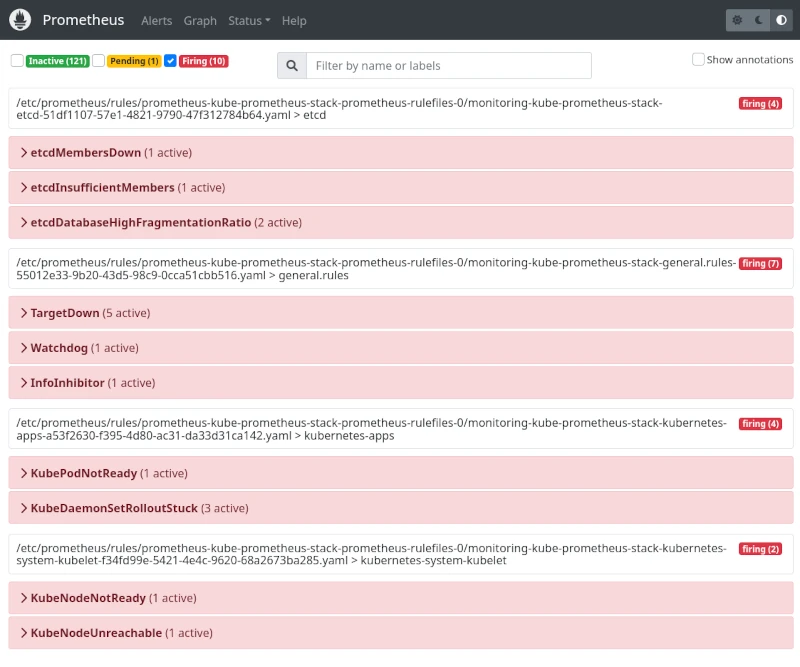
Au bout d’un moment, on a bien des alertes qui sont en “Firing” côté Prometheus et on les retrouve également sur l’Alertmanager:

Les petits trucs à connaître
Récupérer les métriques de tous les ServiceMonitor / PodMonitor du cluster
Par défaut la Custom Resource Prometheus déployée par le chart kube-prometheus-stack est configurée pour ne récupérer que les ServiceMonitor et PodMonitor qui ont été déployés par ce dernier. Il est possible de définir une autre ressource Prometheus qui ciblera les ServiceMonitor / PodMonitor de notre applicatif, mais on peut souvent se contenter d’un seul Prometheus qui récupère l’ensemble des métriques.
Pour cibler tous les ServiceMonitor/PodMonitor du cluster, il suffit de déployer le chart avec les values suivantes :
prometheus:
prometheusSpec:
serviceMonitorSelectorNilUsesHelmValues: false
podMonitorSelectorNilUsesHelmValues: false
Si les values pour serviceMonitorSelector et podMonitorSelector n’ont pas été modifiées, ce sera cette valeur par défaut ({}) qui sera utilisée pour sélectionner toutes les ressources.
Exposer Grafana, Alertmanager et Prometheus via un ingress
Accéder aux WebUI via un port-forward peut bien nous dépanner, mais pour une utilisation au jour le jour, configurer un ingress est plus pratique.
Pour ce faire, il faut utiliser :
grafana:
ingress:
enabled: true
ingressClassName: nginx
pathType: Prefix
hosts:
- grafana.domain.com
alertmanager:
ingress:
enabled: true
ingressClassName: nginx
pathType: Prefix
hosts:
- alertmanager.domain.com
prometheus:
ingress:
enabled: true
ingressClassName: nginx
pathType: Prefix
hosts:
- prometheus.domain.com
Le cas des cloud-provider
Quand on utilise un Kubernetes managé chez un cloud-provider, généralement on n’a pas le control-plane. Pour éviter d’avoir des éléments déployés inutilement et surtout les alertes qui indiquent que certains éléments du control-plane ne tournent pas, il suffit de les désactiver explicitement :
kubeEtcd:
enabled: false
kubeControllerManager:
enabled: false
kubeScheduler:
enabled: false
kubeProxy:
enabled: false
À noter que l’on désactive également kube-proxy, car souvent le CNI (Container Network Interface) par défaut du cloud-provider le remplace. On peut par contre conserver l’API Server qui reste accessible et qui peut fournir des métriques intéressantes (mais volumineuses). Si on souhaite le désactiver lui aussi :
kubeApiServer:
enabled: false
Volume persistant
Si l’on veut conserver les métriques entre chaque redémarrage du pod, il faut lui configurer un volume persistant, même chose pour Alertmanager si on veut conserver les silences ou Grafana pour conserver les modifications :
prometheus:
prometheusSpec:
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: my-storage-class
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 20Gi
alertmanager:
alertmanagerSpec:
storage:
volumeClaimTemplate:
spec:
storageClassName: my-storage-class
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 5Gi
grafana:
persistence:
enabled: true
type: statefulset
storageClassName: my-storage-class
Conclusion
Ça y est ! Nous avons maintenant une stack complète de supervision et d’alerting, le tout à la sauce K8S, c’est-à-dire par et pour le cluster Kube. C’était une bonne petite montagne à gravir, mais heureusement le chart kube-prometheus-stack est un peu notre Sam Gamegie qui nous porte sur ses épaules !
De la même manière que l’univers de Tolkien semble être un puit sans fond pour Hollywood, il reste encore beaucoup de sujets à aborder autour de Prometheus : le stockage de métriques sur le long terme, la haute disponibilité ou une utilisation plus avancée du chart kube-prometheus-stack. A suivre bientôt dans notre prochain article de la série !
Ne ratez pas nos prochains articles DevOps et Cloud Native! Suivez Enix sur Linkedin!