
Cet article est le premier d’une série de 3 sur le monitoring avec un focus sur Thanos.
- Partie 1 : “Thanos : stockage des métriques Prometheus sur le long terme”
- Partie 2 : “Déployer Thanos et Prometheus sur un cluster K8s”
- Partie 3 : “Thanos : agrégation de plusieurs Prometheus”
Ce premier article présente Thanos utilisé pour la collecte de métriques Prometheus sur le long terme.
Par défaut, la durée de rétention des métriques Prometheus est de 15 jours. Pour les conserver plus longtemps (des mois, voire des années), le premier réflexe tentant serait d’augmenter la durée de rétention de Prometheus. On lit pourtant souvent qu’il n’est pas conçu pour ça et qu’il faut un composant supplémentaire comme Thanos. Pourquoi ?
Prometheus : stockage courte durée par design
Prometheus a choisi de garder un stockage des métriques simple, sur le disque local de l’instance.
One of our goals was to run a Prometheus server with millions of time series and tens of thousands of samples ingested per second on a single server using its local disk. You might think everything should be distributed-something nowadays, but distributed systems demand payment in complexity and operational burdens.
On profite ainsi d’un stockage performant avec un déploiement facilité de Prometheus.
Par contre, l’espace disque nécessaire va augmenter avec la quantité de métriques à conserver. De nos jours, les prix du Téraoctet sont plutôt abordables, mais il faut aussi penser à la redondance (un disque peut tomber en panne) ou à la corruption de données (plus on a de données, plus la probabilité d’avoir des données corrompues est grande). Rien d’insurmontable, mais ceci représente un coût.
Again, Prometheus’s local storage is not intended to be durable long-term storage; external solutions offer extended retention and data durability.
Un autre élément à considérer est la quantité de données nécessaires pour répondre à une requête. Pour grapher l’historique d’une métrique sur un an, avec Prometheus qui interroge un exporter toutes les minutes, il faudra récupérer 60m*24h*365j points. Sur un dashboard Grafana complet, la quantité totale de points à récupérer peut rapidement devenir élevée et consommer beaucoup de ressources et augmenter le temps d’affichage .
Même si techniquement Prometheus permet de stocker des métriques sur une longue durée, les bonnes pratiques et les contraintes opérationnelles et budgétaires incitent donc à utiliser un autre composant plus adapté comme Thanos.
![]()
Concept et fonctionnement de Thanos avec Prometheus
Thanos est séparé en plusieurs composants, avec chacun sa tâche et qui peuvent scaler indépendamment les uns des autres pour gérer la charge si nécessaire.
Le tout s’articule autour de deux éléments :
- Un stockage objet pour garder tout l’historique des métriques et quelques metadata
- Une interface de communication en gRPC nommée StoreAPI, pour permettre les échanges inter-composants
Dans un fonctionnement classique, Prometheus s’occupe de récupérer les métriques depuis les exporter et d’envoyer les alertes sur Alertmanager. On va ici rajouter a minima les composants suivants :
- un Sidecar à Prometheus, pour exposer les métriques récentes et les envoyer dans le stockage objet
- une Store Gateway pour l’accès à l’historique des métriques depuis le stockage objet
- un Query (ou Querier) pour accéder aux métriques historiques depuis la Store Gateway et aux métriques récentes via le Sidecar
- un Compactor pour gérer la rétention et optimiser les métriques dans le stockage objet
Un exemple de déploiement simplifié (version plus complete)
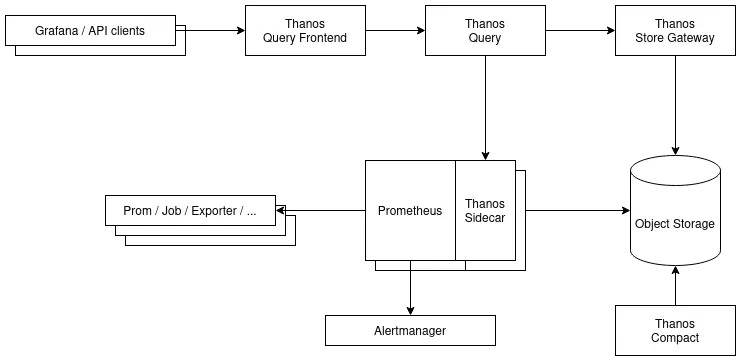
Thanos Sidecar : upload de l’historique dans le stockage objet et auto-reload
Il s’agit d’un composant qui tourne à côté du Prometheus. Le Thanos Sidecar va remplir trois fonctions :
- Envoyer dans le stockage objet les blocs de métriques (par défaut Prometheus en crée un toutes les deux heures), pour le stockage à long terme ;
- Surveiller la configuration et les rules Prometheus, pour relancer le serveur en cas de changement ;
- Exposer les métriques sur la StoreAPI, pour requêter les métriques récentes qui n’ont pas encore été envoyées dans le stockage objet.
Thanos Store Gateway : l’accès aux métriques dans le stockage objet
Une fois dans le stockage objet, il faut pouvoir exploiter les métriques de la même façon que celles présentes sur le stockage local de Prometheus. C’est le rôle du Thanos Store Gateway. Il sert de passerelle avec le stockage objet et l’expose via la StoreAPI (en lecture uniquement).
Par défaut, la Store Gateway s’occupe de l’intégralité des données dans le stockage objet. Mais pour gérer plus efficacement les gros volumes de données, il est également possible de faire du sharding.
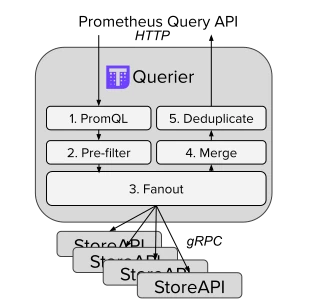
Thanos Query : l’interface PromQL/StoreAPI
Le Thanos Query est le composant qui va faire l’interface entre les programmes qui utilisent l’API de Prometheus pour faire des requêtes PromQL (comme Grafana) et la StoreAPI exposée par les différents composants Thanos (ou des programmes tiers qui implémentent la StoreAPI).
En plus d’offrir une vue globale des différentes StoreAPI (par exemple plusieurs Prometheus avec un Thanos sidecar), le Thanos Query offre des fonctionnalités utiles :
- la dé-duplication des métriques (dans le cas de Prometheus en haute disponibilité)
- le downsampling automatique (pour réduire la quantité de données brutes récupérées lors d’une requête PromQL)
- la gestion de la concurrence des requêtes pour utiliser au mieux le côté distribué de Thanos.
Une interface web similaire à celle de Prometheus permet également de faire des requêtes directement.
Thanos Compactor : compaction, downsampling et rétention
Compaction
Par défaut, les blocs qui contiennent les métriques sont générés toute les 2 heures et envoyés sur le stockage objet. Prometheus compacte ces blocs pour optimiser l’espace : au bout d’un certain temps, ils sont fusionnés pour mutualiser les structures communes. Avec Thanos, c’est le Compactor qui va reprendre ce travail.
Downsampling
Le Compactor s’occupe également du downsampling, à savoir créer des versions agrégées des métriques sur une période de temps donnée. Thanos crée des agrégations avec un point de donnée toutes les cinq minutes et un autre toutes les heures.
Ceci présente l’avantage de réduire la quantité de données à récupérer lorsqu’il n’y a pas besoin de précision. Par exemple, avec une métrique récoltée toutes les minutes, avec les données brutes il nous faudrait 60m*24h*365j points pour grapher sur un an. Avec la version agrégée d’une heure, on divise par 60 le nombre de points à récupérer : on économise ainsi la donnée qui transite sur le réseau et on obtient un rendu plus rapide.
Si l’on a besoin de zoomer sur une partie du graphique, on va reprendre des valeurs plus précises : en fonction de la résolution demandée, l’agrégation de points sur cinq minutes ou bien les données brutes.
Rétention
Le Thanos compactor s’occupe également d’appliquer la durée de rétention et de supprimer les blocs du stockage objet une fois cette durée dépassée.
Composants Thanos optionnels
Thanos Query Frontend : cache et optimisations des requêtes PromQL
Le Thanos Query Frontend se place devant le Thanos Query et offre des fonctionnalités pour améliorer le temps de réponses des requêtes PromQL :
- du cache pour les résultats, pour les réutiliser (même partiellement) dans les requêtes futures,
- une gestion des erreurs temporaires , avec une nouvelle tentative pour obtenir le résultat,
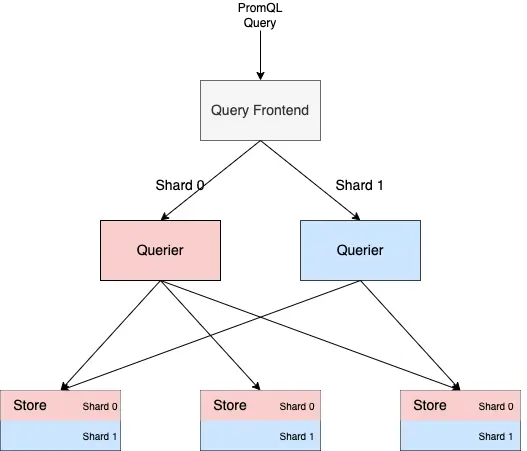
- du sharding à la volée sur les requêtes pour mieux les paralléliser, par exemple découper une requête sur une semaine en plusieurs requêtes sur une journée.
Thanos Receiver : récupération des métriques via remote_write
Dans certains cas, il n’est pas possible pour le Thanos Query de joindre directement le Thanos sidecar attaché à un Prometheus, par exemple avec une plateforme sur un réseau isolé. Dans cette situation, on peut quand même utiliser le sidecar pour pousser les blocs de métriques dans le stockage objet, mais on perd l’accès aux métriques récentes que Prometheus n’a pas encore consolidées dans un bloc.
Pour palier à ce problème, on peut utiliser Thanos Receiver qui implémente l’API Remote Write de Prometheus. Il suffit de configurer le remote_write côté Prometheus pour envoyer sur le Thanos Receiver et ce dernier s’occupera comme le sidecar de placer les métriques sur le stockage objet.
Thanos Rule : l’évaluation des recording/alerting rules en dehors de Prometheus
La gestion des recording et alertings rules est normalement fait par Prometheus. Dans certains cas, on peut souhaiter déléguer cette partie à Thanos, par exemple si l’on veut faire des rules qui ciblent les métriques de deux Prometheus différents ou sur une durée de rétention plus longue que celle du Prometheus.
C’est ce que permet Thanos Rule (ou Thanos Ruler), qui va utiliser les métriques disponible sur le Thanos Query pour évaluer ses rules. Attention cependant, ce n’est pas complètement sans risques car on ajoute des composants intermédiaires qui peuvent potentiellement être indisponibles.
On passe aux travaux pratiques ?
L’article suivant de cette série sur le monitoring décrit dans le détail comment déployer ces composants Prometheus et Thanos sur un cluster Kubernetes fraîchement monitoré avec kube-prometheus-stack.
Ne ratez pas nos prochains articles DevOps et Cloud Native! Suivez Enix sur Linkedin!