
(Article mis à jour le 10/02/2025)
Si vous gérez des clusters Kubernetes au quotidien, il vous est peut-être arrivé de penser que vous passiez beaucoup trop de temps sur vos commandes kubectl.
Pour lister des pods ou des deployments, changer de namespace, afficher les logs de vos conteneurs, éditer ou supprimer certaines ressources, etc. Ces actions sont relativement simples mais elles peuvent rapidement devenir rébarbatives (vous pouvez jeter un oeil à mes articles sur les commandes kubectl et les commences kubectl avancées).
K9s est un outil puissant qui permet de réaliser bien plus simplement ces différentes actions sur vos clusters. Cet article présente K9s par l’exemple : sur une stack Prometheus et avec des démos en format vidéo.
K9s, c’est quoi ?
K9s, à l’instar de Lens, est un outil de gestion de cluster Kubernetes via une interface utilisateur.
K9s surveille votre cluster Kubernetes de façon permanente. Il vous offrira notamment :
- Une bonne compréhension de votre cluster K8s et une bonne visibilité de l’état des ressources
- Une navigation facilitée à travers les ressources du cluster
- Une possibilité d’interagir simplement avec ces ressources
La principale différence entre K9s et Lens est que K9s s’execute directement dans un terminal, tandis que Lens est une application de bureau classique. Les deux solutions sont très intéressantes et possèdent leurs propres avantages. Aujourd’hui, nous allons nous intéresser ensemble à K9s !
Dans les parties suivantes, nous allons découvrir comment utiliser K9s dans un exemple concret sur une stack Prometheus. Nous verrons les fonctionnalités de bases de K9s ainsi que des fonctionnalités avancées. Le tout sera démontré sur un cluster K8s pré-configuré sur notre cloud Enix comprenant 4 nodes dont 3 workers et 1 master.
Grâce aux petites vidéos de démo intégrées, vous n’avez donc pas besoin de votre cluster K8s pour suivre cet article.
K9s : installation et accès à un cluster Kubernetes
Imaginez que vous rejoignez une nouvelle équipe au sein de votre entreprise. Vous avez la responsabilité d’un cluster de production auquel vous n’avez jamais eu accès auparavant. Vos collègues vous fournissent un fichier .kube/config.yaml pour vous permettre d’accéder à ce cluster Kubernetes. Sans plus attendre, allons y jeter un coup d’oeil !
Commençons par installer K9s, pour cela, je vous invite à suivre ce guide expliquant comment installer K9s sur MacOS, Linux et Windows.
Une fois K9s installé, vous pouvez le lancer depuis le terminal avec la commande k9s. Si vous utilisez plusieurs fichiers config.yaml, vous pouvez choisir lequel utiliser grâce au flag --kubeconfig, comme suit k9s --kubeconfig ~/.kube/config.yaml. Si plusieurs contextes sont disponibles, il vous sera demandé d’en choisir un. Dans le cas contraire, K9s affichera par défaut la liste des pods du cluster dans le namespace default.
Lors d’une réouverture, K9s affichera le dernier type de ressources consulté, dans le dernier namespace sélectionné.
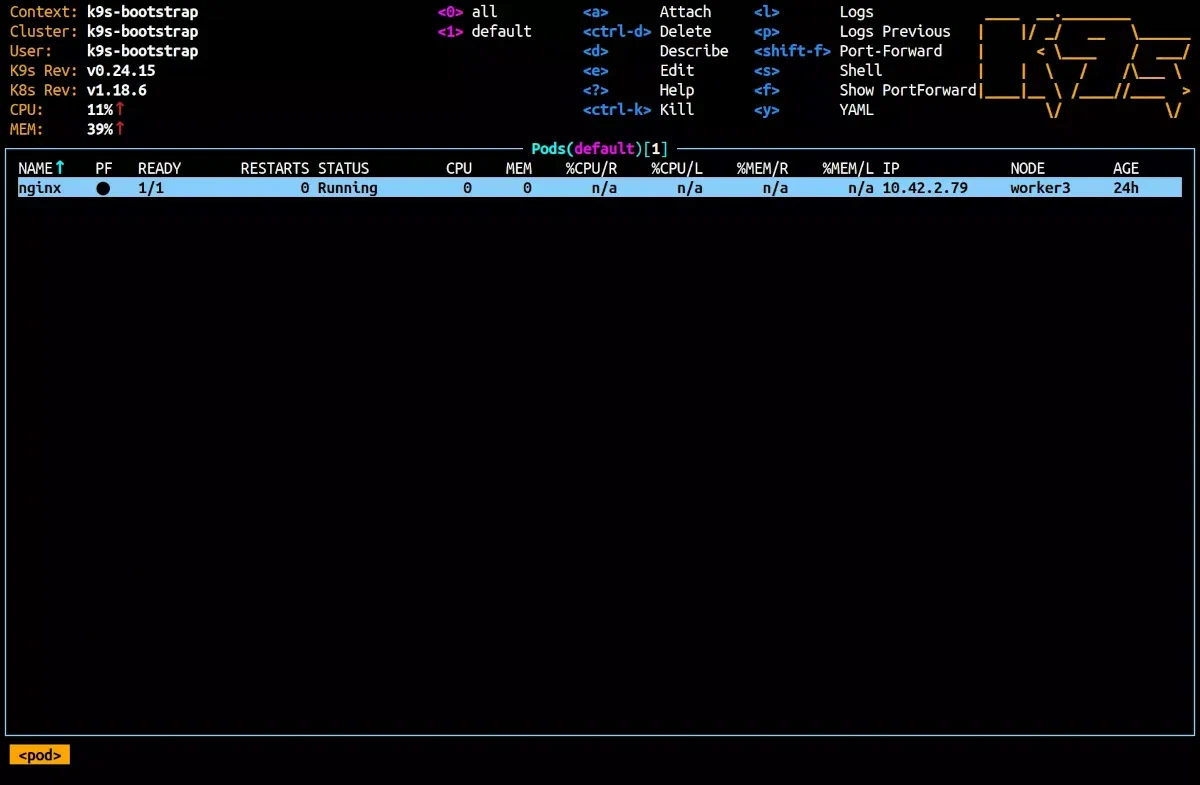 Le pod Nginx visible ci-dessus est ici à titre d'exemple, nous n'allons pas intéragir avec lui durant cet article.
Le pod Nginx visible ci-dessus est ici à titre d'exemple, nous n'allons pas intéragir avec lui durant cet article.
K9s affiche différentes informations sur les ressources consultées. Nous y voyons par exemple, pour un pod : son âge, le node sur lequel il tourne, la quantité de RAM utilisée ou encore son nom. Ces informations sont normalement accessibles via kubectl get pods et kubectl top pods. Elles sont rafraîchies par défaut toutes les 2 secondes, mais ce paramètre peut être changé via le flag --refresh. Pour un refresh toutes les secondes, il suffit d’entrer k9s --refresh=1.
Bien qu’on puisse configurer le rerfesh-rate via la CLI, ce paramètre (et beaucoup d’autres) peuvent-être configurés une bonne fois pour toute via le fichier de configuration de k9s ($XDG_CONFIG_HOME/k9s/config.yaml) via l’entrée k9s.refreshRate. La commande k9s info permet de trouver la localisation des différents fichiers de configuration. La liste des options disponible est documentée sur le site officiel. On y retrouve notamment les options de configuration des hotkeys et des aliases présentés plus loin dans les commandes avancées.
La partie haute de la UI de K9s contient quelques informations sur K9s lui-même et sur le cluster observé. Certaines des commandes disponibles s’y trouvent également. Pour voir toutes les commandes, appuyez sur la touche h.

Nous pouvons également voir des noms précédés de nombres. Il s’agit là de raccourcis de filtrage par namespace. La touche 0 permet d’afficher les ressources présentes dans tous les namespaces, 1 permet d’afficher le namespace default et d’autres raccourcis sont ajoutés au fur et à mesure que vous naviguez à travers les namespaces.
En affichant les pods de tous les namespaces, nous pouvons remarquer qu’un pod se trouve être en rouge. La couleur des lignes donne des informations sur la ressource observée. Par exemple, si un pod est cyan, c’est qu’il se trouve dans l’état Running, rouge signifie une erreur, violet que le pod est en train d’être détruit.

K9s et Prometheus : séance de debug
Maintenant que nous avons pris nos marques sur ce nouveau cluster, il serait dommage de s’arrêter là. Attelons-nous à déboguer ce fameux pod !
Il y a beaucoup de pods visibles dans notre liste. Pour commencer, changeons de namespace. Pour cela, appuyez sur la touche :, puis entrez namespace (ou un alias, comme ns par exemple), appuyez sur la touche enter. Vous pouvez maintenant voir les namespaces disponibles sur le cluster. Sélectionnons le namespace monitoring, qui est celui dans lequel se trouve le pod en erreur.
Pour filtrer les resources visibles, le raccourci / permet d’effectuer une recherche, comme on en a l’habitude avec les commandes man, less, etc…
C’est déjà beaucoup mieux. Maintenant, nous pourrions lancer un describe sur le pod en question pour identifier les events qui pourraient nous être utiles intéressants.
Inspection d’un pod
Allez sur le pod en erreur, et faites d. Vous voyez dans les events une succession de “Back-off restarting failed container”, ce qui est en accord avec ce que l’on voit dans la colonne status du pod (CrashLoopBackOff).
Allons voir les logs pour en savoir plus. Quittez la vue du describe avec la touche ESC, puis faites l pour afficher les logs du pod. Vous voyez maintenant les logs de tous les conteneurs du pod.
Quittons cette vue, puis entrons dans les détails du pod avec la touche entrée. Nous pouvons maintenant afficher les logs de chaque conteneur individuellement, et voir certaines informations supplémentaires telles que les images utilisées par les conteneurs. Affichons les logs du conteneur en rouge.
level=error ts=2021-08-30T15:34:17.018Z caller=main.go:347 msg="Error loading config (--config.file=/etc/config/prometheus.ym)" err="open /etc/config/prometheus.ym: no such file or directory"
Correction d’un deployment
Le path du fichier de configuration ne semble pas bon, sûrement une erreur dans les arguments du programme exécuté dans le conteneur. Allons voir la configuration de ce pod. Quittez la vue des logs et des conteneurs, puis faites y pour affichez le yaml du pod.
Effectivement, le flag --config.file=/etc/config/prometheus.ym est mal écrit, une lettre est manquante à l’extension du fichier de configuration. Allons corriger cela, vous savez que le pod en question a été créé via un deployment, revenez donc à la liste des pods, puis appuyez sur la touche :, et entrez deployments. Allez sur le deployment en rouge et faites e pour l’éditer. Ajoutez le “l” manquant à l’extension puis enregistrez et quittez.
Le pod est enfin passé en cyan et son status est Running ! Nous allons maintenant essayer d’accéder au dashboard Prometheus pour vérifier que tout fonctionne.
Accès au dashboard Prometheus grâce au port-forwarding
Pour accéder au dashboard Prometheus, on n’a pas vraiment envie de se prendre la tête à configurer des ingress, nous allons plutôt faire du port forwarding. Dans k9s, shift+f sur un pod permet de le mettre en place. Faites shift+f sur le pod prom-prometheus-server et gardez la configuration par défaut. Le dashboard Prometheus est maintenant disponible à l’adresse localhost:9090.
Dans la vidéo ci-dessus, on supprime à la fin le port-forwarding à titre d'exemple seulement. Dans le cadre du déroulé de cet article, partons du principe que nous ne le supprimerons pas réellement.
En jetant un oeil au dashboard, nous pouvons nous rendre compte qu’aucune métrique n’est disponible. On nous avait pourtant dit que des métriques étaient déjà en place ! Mais quelque chose me dit qu’il doit y avoir un souci du côté des exporteurs… 😉.
Actions sur des groupes de ressources
En partant de cette piste tout droit sortie d’un chapeau magique 🧙, nous pourrions penser que supprimer toutes les instances d’exporteurs Prometheus afin qu’ils soient recréés proprement par leur daemonset serait une solution envisageable de dernier recours. Mais juste parce qu’on a envie de jouer un peu avec notre nouvel outil, faisons le test.
Pour supprimer les pods plus rapidement, vous pouvez commencer par les sélectionner, pour enfin les supprimer en groupe. Pour sélectionner un pod (ou tout autre type de ressource), appuyez sur espace, pareil pour le désélectionner. Vous pouvez sélectionner plusieurs pod en même temps, d’ailleurs si vous faites ctrl+espace après avoir sélectionné un premier pod, tous les pods se trouvant entre les deux pods en question seront sélectionnés. Une fois votre sélection effectuée, vous pouvez effectuer votre action groupée, tel que supprimer les pods sélectionnés.
Ouverture d’un shell dans un conteneur
Bon, les pods sont revenus, mais nous n’avons toujours pas de métriques dans notre dashboard ! Essayons, depuis un conteneur du cluster, de récupérer les métriques d’un exporter. Pour cela, il suffit d’appuyer sur la touche s en survolant un pod ou un conteneur pour y lancer un shell. Nous pouvons ensuite requêter le service en question : curl prom-prometheus-node-exporter:9100/metrics.
Les pods des exporters tournent correctement, cependant, leurs APIs ne sont manifestement pas accessibles, probablement un souci de configuration de service.
En inspectant le service monitoring/prom-prometheus-node-exporter, nous constatons une typo dans la configuration du selector avec un double “o” dans component: noode-exporter. Corrigeons cela et appliquons la modification. Réitérons la manipulation précédente, et cette fois-ci, nous arrivons bien à curl le service et les métriques sont enfin disponibles sur le dashboard.
Commandes K9s spéciales
En plus des commandes qui permettent de sélectionner un type de ressource comme les configmaps ou les ingresses, K9s possède quelques commandes “spéciales” qui permettent d’observer le cluster sous un autre angle qu’un simple listing de ressources.
K9s workloads
Ajoutée dans la version v0.30.0, cette commande workloads permet de lister d’un seul coup les daemonsets, deployments, replicasets, pods et services d’un cluster. Pratique pour avoir rapidement une idée de ce qui tourne sur votre cluster et de quelle manière (daemonset, deployment ?) sans avoir à parcourir chaque ressource indépendament.
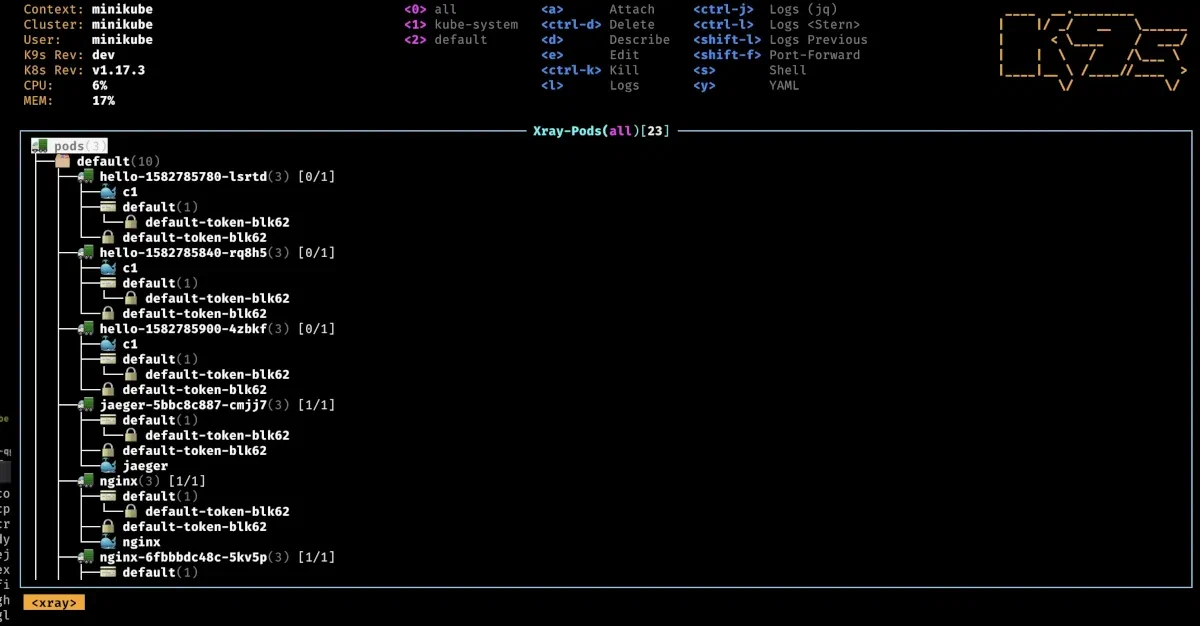
K9s xray <ressource>
Xray permet d’afficher une vue en arbre d’un certain type de ressource et des ressources liées. Très pratique pour avoir rapidement une vue d’ensemble. xray pods vous affichera par exemple la liste des containers de chaque pods, les configmaps utilisées, et autres encore. Attention cependant si vous avez un cluster chargé, cette commande risque de mettre un peu de temps à s’executer…
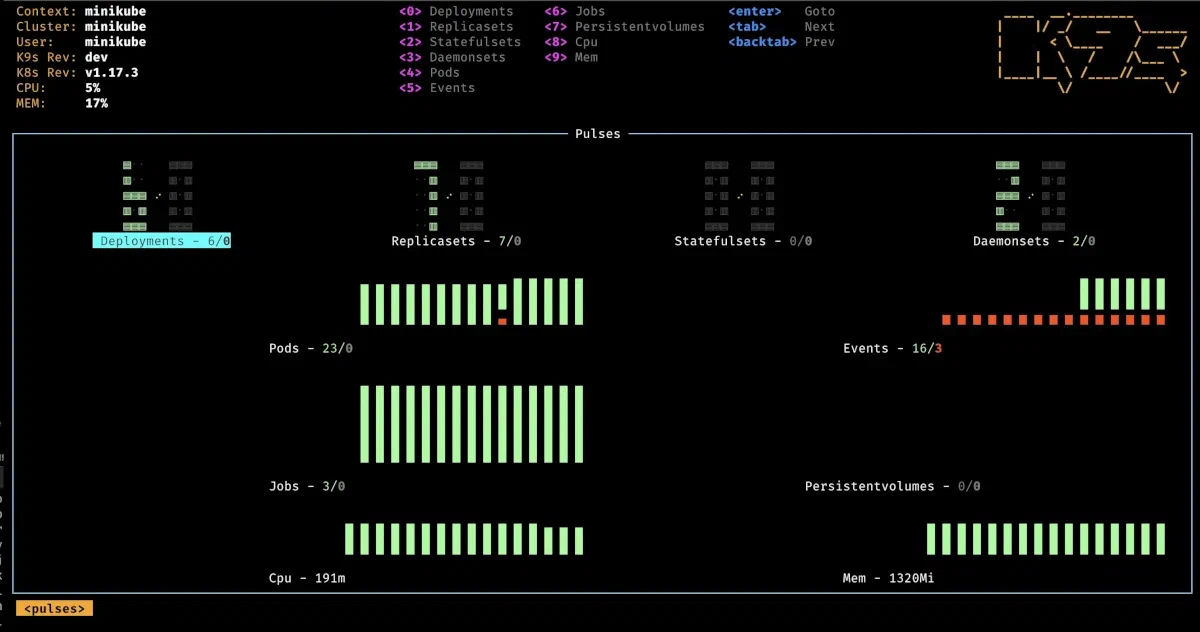
K9s pulse
La commande pulse permet quand à elle de rapidement observer différentes métriques de votre cluster. Attention, cette fonctionnalité nécessite d’avoir un metric server installé au sein de votre cluster et en bon état de marche.
Configurations K9s avancées
Au-delà des configurations basiques telles que le refresh rate (k9s.refreshRate), la configuration du pod à créer pour lancer un shell sur un node (k9s.shellPod) ou encore activer le support de la souris (k9s.ui.enableMouse), k9s permet une personalisation avancée via des raccourcis et des aliases configurables.
️⚠️ Les fichier de configurations de ces deux fonctionnalités sont séparés de la configuration de base, ces deux fichiers sont nommés
aliases.yamlethotkeys.yaml, vous pouvez retrouver le chemain exact grace à la commandek9s info.
Aliases
Les aliases permettent de remplacer une longue commande ou nom de resource par un diminutif plus court. N’importe quelle commande entrée dans la barre de commande de k9s peut être aliassée. Par exemple, on peut imaginer configurer un alias dns qui listerai tous les pods du namespace kube-system ayant le label k8s-app=kube-dns.
aliases:
dns: pod kube-system k8s-app=kube-dns
Ainsi, taper dns lancera la commande pod kube-system k8s-app=kube-dns.
Hotkeys
Les hotkeys, bien qu’apportant la même fonctionnalité que les aliases, sont légèrement différents dans le sens où ils ne demandent pas de taper une commande, un simple raccourci permet d’executer la commande liée. Les aliases peuvent être utilisés depuis des hotkeys.
hotKeys:
shift-0:
shortCut: Shift-0
description: Viewing kube-dns pods in kube-system namespace
command: dns
x:
shortCut: x
description: XRay Deployments
command: xray deploy
Ainsi, on pourra executer l’alias dns avec shift+0 et afficher le xray des deployments avec la touche x.
Les hotkeys sont visibles depuis l’aide de k9s (?).
Bonus : les skins K9s !
Un dernier aspect de la configuration pour les plus raffinés d’entre vous 🤌 Les skins K9s ! 🎨
Avec les skins, vous pouvez configurer absolument toutes les couleurs de votre k9s. Pour cela, il suffit d’indiquer le skin que vous souhaitez utiliser dans la configuration générale de k9s via l’entrée k9s.ui.skin, par exemple k9s.ui.skin: dracula pour activer le skin dracula.yaml. Vous pouvez ajouter autant de skins que vous voulez dans le dossier $XDG_CONFIG_HOME/k9s/skins. Vous trouverez toute une palanquée de skins pré-configurés dans le repository de k9s, dans le dossier skins.
K9s, en résumé
Avec cette petite mise en situation, nous avons pu découvrir différentes fonctionnalités et cas d’usage de K9s.
Parmi ceux-ci, on note le listing des ressources, l’édition ou la supression de celles-ci, ainsi que des fonctionnalités avancées telles que le port-forwarding ou l’ouverture d’un shell dans un conteneur. Nous les utilisons au quotidien chez Enix, notamment pour l’infogérance Kubernetes avec nos clients.
Ceci n’est pas exhaustif, K9s propose bien d’autres fonctionnalités pour vous aider au quotidien à gérer vos clusters K8s. Pour aller plus loin, je vous invite donc à jeter un œil à la documentation de K9s qui comprend de nombreux tutoriels et exemples.
Ne ratez pas nos prochains articles DevOps et Cloud Native! Suivez Enix sur Linkedin!