
Aujourd’hui, sur notre blog Enix, je viens vous parler technique mais sur un sujet pas banal : les cartes postales des années 20. Pas très Cloud Native, vous allez me dire, mais c’est un projet de préservation historique auquel je contribue régulièrement et qui présente plein de challenges techniques intéressants comme on les aime !
Le projet en question, c’est EphemeraSearch. Le projet est basé sur une stack Django avec un frontend en React. Choix original au premier abord, mais qui reflète bien l’évolution que de nombreuses équipes ont traversé ces dernières années : on part d’un framework classique type Rails, Django, Symfony… Et puis on saupoudre ça de single page app, HTML5, React, un coup de refactoring pour avoir une API REST… Et on y est.
C’est dans ce cadre que je me suis retrouvé à faire de l’optimisation de performances. Il s’agit d’un « projet passion » sans lien direct avec nos activités chez Enix ; mais Django, c’est aussi ce qu’on utilise pour le backend de notre service SaaS Blinky et son fameux gyrophare DevOps connecté (actuellement en phase beta). Donc on s’est dit que ça avait du sens et que ça pourrait rendre service de partager ce retex ici !
Même s’il y a peu de chances que vous tombiez exactement sur la même situation, la technique utilisée pour identifier l’origine du problème est applicable à d’autres situations ; et la méthodologie générale est facilement transposable à d’autres frameworks et d’autres langages.
Alors, on y va ? C’est parti !
Les données du problème
Sans entrer dans les détails, EphemeraSearch est une archive de documents historiques - pour l’instant, principalement des cartes postales de la première moitié du XXe siècle. Les cartes postales sont scannées, puis mises en ligne sur le site. (Au passage, c’est gratuit ; donc si vous êtes passionné·e d’Histoire ou de généalogie, n’hésitez pas à aller jeter un coup d’œil sur le site!)
Les cartes postales sont ensuite transcrites et indexées, ce qui permet de chercher à partir du nom d’un de ses ancêtres, ou bien une adresse où ils ont vécu, et avec un peu de chance, de trouver des cartes postales qu’ils ont reçues.
On a récemment mis en production une intégration avec eBay, permettant aux gens vendant des cartes postales anciennes sur eBay d’ajouter automatiquement leurs collections au site en quelques clics. Résultat, plusieurs milliers de cartes postales ont été intégrées au site. Super ! 🎉 Bon, sauf que au passage, les performances en ont pris un coup. Pas super ! 😭
Quand on en est arrivé au point où le simple fait d’afficher une carte postale prenait plusieurs secondes, il est devenu clair qu’il fallait faire quelque chose. Et vite.
Au départ, quand on observe un ralentissement après avoir ajouté des données, on peut penser à un problème d’index dans la base SQL. Mais après une rapide inspection des index, tout paraissait en règle. Et surtout, charger une carte postale individuellement (par exemple avec l’ORM Django) était instantané. Il semblait donc que le problème était ailleurs. Mais où ?
Premières analyses de performance
Grâce à notre APM, on a réussi à voir presque tout de suite qu’il y avait notamment une requête qui prenait beaucoup plus de temps que prévu : la requête API pour récupérer une carte postale.
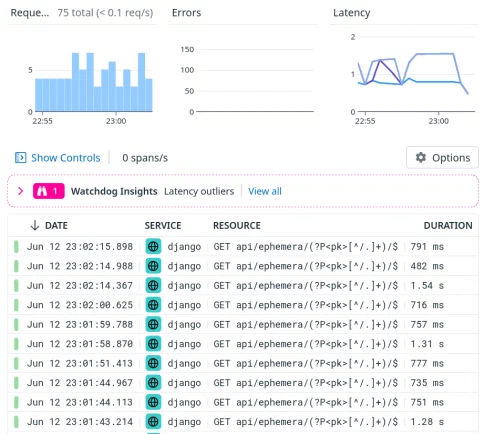
Normalement, cette requête devrait prendre entre 10 et 100 millisecondes. Pas entre 0.5 et 1.5 secondes … Cette requête pourrait expliquer les ralentissements observés !
On a jeté un œil au flame graph de la requête, qui montre le détail des appels de fonction effectués au sein de la requête. Malheureusement, on a vite déchanté :

On dirait que l’appel de la méthode api.viewsets.get_serializer prend très longtemps, mais on ne voit pas bien pourquoi. Et si on essaie d’analyser cette fonction plus en profondeur, on tombe sur moult appels individuels (concrètement : des centaines de milliers) mais rien qui saute aux yeux.
Spoilers alert Alerte divulgâchage : en fait, le problème était exactement là … Mais on ne l’a malheureusement pas vu tout de suite, hélas !
Reproduire le bug en local
À ce stade-là, on était aux limites de ce qu’on pouvait faire en bricolant avec les environnements de prod et pré-prod. On a donc décidé de reproduire le problème localement.
Cela permet d’y voir un peu plus clair, et surtout, cela permet de sortir une panoplie d’outils plus vaste (par exemple, mettre des points d’arrêt dans un debugger, comme on va le voir un peu plus tard).
On a commencé par mesurer les performances de la fameuse requête afin de partir d’une valeur de base. (On a simplifié la sortie de la commande ci-dessous, pour un peu plus de clarté.)
$ hey -n 10 -c 1 "http://localhost:8000/api/ephemera/..."
Summary:
...
Average: 0.3526 secs
...
Au passage, si vous ne connaissez pas encore hey, on vous le recommande chaudement : c’est une sorte de Apache Bench moderne, qui permet d’obtenir très rapidement des histogrammes de la latence d’un service sous diverses conditions de charge.
On note que la requête qui prenait tout à l’heure 800ms en production ne prend que 350ms en local. Ça peut paraître un peu surprenant au départ : pourquoi est-ce qu’une pauvre machine de dev serait plus rapide qu’un bon gros serveur de prod ?
Il peut y avoir plusieurs explications :
- notre machine de dev n’est pas trop chargée (à part Slack et Chrome, qu’est-ce qui prend du CPU sur une station de travail de nos jours?😁) et surtout, la plupart des CPU Intel/AMD modernes sont capables de “booster” leur vitesse d’horloge quand il n’y a qu’un seul cœur qui est sollicité - ce qui donne de bons résultats en exécution single-thread, comparé à un serveur avec plusieurs dizaines de cœurs mais qui sont tous sollicités en permanence ;
- dans notre environnement de dev, la base de données tourne en local, ce qui veut dire une latence plus faible, et cette faible latence peut se traduire par une amélioration des performances, surtout si notre requête API entraîne beaucoup de requêtes SQL (et autant d’aller-retours avec la base de données) ;
- …
Plus tard, on découvrira que le problème entraînait effectivement une consommation excessive de CPU. Ça explique probablement pourquoi, rétrospectivement, notre environnement local s’en sortait bien comparé à la prod.
Et on cherche, et on cherche …
Notre appli web n’est pas en Django “pur” (avec des vues générant du HTML à partir de templates). En fait, c’est une app React qui communique avec une API, elle-même implémentée par-dessus Django grâce à Django REST Framework (ou DRF pour les intimes).
DRF, c’est bien (mangez-en) (sérieusement!) parce que ça facilite justement ce travail d’implémentation d’API REST, surtout quand on a besoin de personnaliser la représentation des objets (dans notre cas, leur sérialisation en JSON, avec plus ou moins de champs inclus selon le type de requêtes) mais aussi la validation de ces objets (pour traiter de manière sécurisée des modifications via des requêtes POST, PUT, ou PATCH, par exemple).
Après avoir fait quelques recherches, on est tombé sur deux excellents articles parlant de l’optimisation des performances avec DRF :
- Improve Serialization Performance in Django Rest Framework par Haki Benita,
- Web API performance: profiling Django REST framework par Tom Christie.
Ces deux blog posts sont très instructifs, mais … ils ne nous ont pas vraiment avancés dans notre quête. En fait, on était même drôlement embêtés, parce dans le blog de Tom Christie, il montre des requêtes dans lesquelles l’interrogation de la base de données prend 66% à 80% du temps. Alors que chez nous, la base de données ne prend que 20% du temps.
Soyons clairs : ça ne veut pas dire qu’on fait des trucs super bien avec la base de données, mais plus vraisemblablement qu’on doit faire des trucs vraiment bien nazes dans le reste du code !
Désolé Mario, ta princesse est dans un autre château. On enchaîne !
Le profiler
On a évalué la performance de nos serializers DRF en important soigneusement à la main les bons modules, en créant les bonnes classes … Un vrai travail d’orfèvre, mais au final, la performance de nos serializers nous paraissait correcte.
(On vous passe le détail de cette expérience, parce que honnêtement ça ne nous a pas avancé des masses, et de toute façon c’est très bien expliqué dans les blog posts évoqués plus haut.)
Arrivés là, on a décidé de faire deux choses.
- D’abord, reproduire dans un interpréteur Python l’exécution de la fameuse requête, en étant le plus proche possible des conditions réelles.
- Ensuite, l’exécuter dans le profiler Python afin de voir où partaient nos précieux cycles CPU.
Commençons par la première partie : reproduire la requête à l’identique (ou en tout cas, de manière très proche à l’original).
Note : pour se faciliter la vie, on a exécuté le code ci-dessous dans l’environnement Django shell_plus.
import django.test
import django.urls
# La fameuse requête, séparée en URI et Query String.
uri = "/api/ephemera/13373/"
qstring = "?img=2&expand=~all&referrer=/ephemera/13373/"
# On construit un objet "request" ..."
factory = django.test.RequestFactory()
request = factory.get(uri+qstring)
# Puis on fait appel au routeur de Django pour trouver
# la vue censée traiter la requête ...
resolvermatch = django.urls.resolve(uri)
# Et on appelle/exécute/invoque la vue. Derechef, hop.
resolvermatch.func(request, *resolvermatch.args, **resolvermatch.kwargs)
# On peut même faire un microbenchmark vite fait grâce à %timeit (vive IPython!)
%timeit resolvermatch.func(request, *resolvermatch.args, **resolvermatch.kwargs)
Avec un peu de chance, l’exemple ci-dessus devrait marcher pour la plupart des requêtes GET, peu importe les applications Django et frameworks additionnels utilisés. C’est très générique. En revanche, il y a deux inconvénients majeurs :
- ça court-circuite la plupart (voire la totalité) des middlewares Django,
- il faut probablement ajouter un peu d’huile de coude si vous voulez adapter ça à autre chose que des
GET.
Dans notre cas, on ne se préoccupait pas du tout des middlewares, parce que l’APM nous avait montré clairement que le temps CPU était consommé par notre application. Ou, pour dire les choses autrement, le surcoût des middlewares était négligeable (ce n’était donc pas là-dedans qu’on pouvait espérer glaner quelque chose).
Prochaine étape : passer notre requête au profiler afin de voir dans quelles fonctions on brûle du CPU. En espérant avoir plus de détails que dans l’APM !
Voilà ce qu’on a utilisé :
import cProfile
cProfile.run(
"for i in range(10): resolvermatch.func(request, *resolvermatch.args, **resolvermatch.kwargs)",
sort="tottime"
)
Quand j’avais besoin de profiler du code Python à la fac (autrement dit, il y a plus de 20 ans🫣) c’est à peu près ce que j’utilisais. Mais heureusement, aujourd’hui, on vit dans une époque plus moderne, et il y a des outils plutôt classes qui permettent d’avoir des visualisations interactives de cette information (plutôt qu’une liste en mode texte à l’ancienne). Par exemple, on peut utiliser SnakeViz ou encore Tuna.
Pour les installer, il suffit d’un rapide pip install, puis on les utilise comme ça :
# D'abord, sauvegarder les informations de profiling dans un fichier
cProfile.run(
"for i in range(10): resolvermatch.func(request, *resolvermatch.args, **resolvermatch.kwargs)",
"/tmp/pstats"
)
# Puis, exécuter snakeviz ou tuna pour charger le fichier
# (ça va lancer un serveur web et ouvrir une page dans notre navigateur)
!snakeviz /tmp/pstats
!tuna /tmp/pstats
(Si vous vous demandez ce que c’est que cette syntaxe bizarre : on utilise IPython, et avec IPython, on peut exécuter une commande shell en la préfixant avec un point d’exclamation. Donc ça veut juste dire “lance snakeviz ou tuna dans un sous-process”.)
Voilà ce que SnakeViz nous a montré :
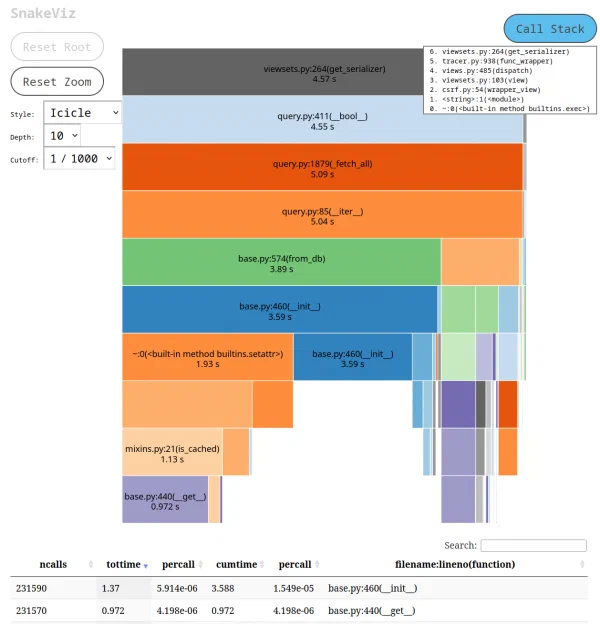
Ce qui a attiré notre attention, c’est les 231 590 appels à base.py:__init__ qu’on peut voir en bas de l’écran.
Mais pourquoi diantre ce bout de code crée-t-il 231 590 nouvelles instances d’objet ? Et puis d’abord, des instances de quelle classe ?!?
Rétrospectivement, à ce moment-là, la réponse aurait du nous sauter aux yeux - mais on ne l’a pas vue tout de suite. (Cher lecteur, chère lectrice, si toi tu as déjà détecté le problème, laisse un commentaire, et abonne-toi à la chaîne bravo ! 🎊🎖️🐍)
Print à la rescousse
On a décidé d’ajouter un bon vieux print dans ce fameux fichier base.py. Plus précisément, il s’agit de django/db/models/base.py, qui se trouve dans le sous-répertoire lib/python-XXX/site-packages de notre virtualenv. Il y a certainement des manières plus élégantes de procéder, mais ça fait le job !
On a modifié le constructeur de la classe Model comme suit :
class Model(AltersData, metaclass=ModelBase):
def __init__(self, *args, **kwargs):
print(self.__class__, args and args[0])
...
Puis, on a répété la requête de test. À chaque fois qu’une classe dérivée de Model était instanciée, on pouvait voir le nom exact de la classe, ainsi que les arguments passés au constructeur. Pratique !
Et là, on a vu que notre requête (qui était censée récupérer les donnés d’une carte postale) allait en fait créer une instance par carte postale présente en base. On avait des dizaines de milliers de lignes comme celles-ci (la classe Ephemeron est celle qui représente nos cartes postales) :
...
<class 'models.Ephemeron'> 896
<class 'models.Ephemeron'> 895
<class 'models.Ephemeron'> 894
<class 'models.Ephemeron'> 893
...
Encore une fois, on aurait pu ou du le voir venir : le nombre d’appels au constructeur base.py:__init__ correspond de très près au nombre de cartes postales qu’on avait dans la base de données à ce moment là ; donc on aurait pu deviner ce qui était instancié. Mais bon, c’est toujours mieux d’avoir une confirmation formelle que de naviguer au pifomètre !
Le debugger vient de rejoindre le chat
Ensuite, il fallait encore trouver ce qui pouvait bien créer toutes ces instances. On a choisi une méthode simple mais efficace : ce bon vieux breakpoint() !
(Au cas où vous ne connaîtriez pas cette astuce : en Python, la fonction breakpoint() invoque le debugger. Par défaut c’est le classique pdb, mais si vous préférez un outil un peu moins spartiate, vous pouvez pip install ipdb puis export PYTHONBREAKPOINT=ipdb.set_trace et à ce moment là breakpoint() utilisera ipdb. Magique, n’est-ce pas ?)
On a donc modifié le constructeur afin d’appeler breakpoint() au tout début du constructeur. Avec une astuce, toutefois : au lieu d’appeler breakpoint() de manière inconditionnelle (ce qui arrêterait le programme à chaque fois qu’on instancie n’importe quel modèle Django), on l’appelle uniquement lors de l’instanciation d’un objet avec une clé primaire de 20000 (car on savait qu’on avait une carte postale avec cet identifiant).
Voilà notre nouveau constructeur. On ajouté une ligne de plus :
class Model(AltersData, metaclass=ModelBase):
def __init__(self, *args, **kwargs):
print(self.__class__, args and args[0])
if args and args[0]==20000: breakpoint()
...
Après ça, on envoie une requête de test supplémentaire. Et c’est le jackpot !
Une fois dans le debugger, on peut parcourir la pile d’appels (avec up et down) et on tombe alors sur ce bout de code :
ipdb> l
285 logger.critical(f"unknown action requested: {self.action}")
286
287 # logger.verbose(f"{self} getting serializer {self.serializer_class}")
288 ret = super(DynSerializerModelViewSet, self).get_serializer(*args, **kwargs)
289 try:
--> 290 if (
291 self.queryset
292 and ret.Meta.model != self.queryset.model
293 and settings.DJANGO_ENV == "development"
294 ):
295 embed(header="wrong models")
Le problème vient du if self.queryset. Quand une expression est utilisée dans une condition (par exemple dans un if), Python tente de convertir cette expression en valeur booléenne (vrai/faux). Quand l’expression est une classe (comme c’est le cas ici, où l’expression est un QuerySet), on appelle la méthode __bool__() de cette classe.
Si on regarde à nouveau la capture d’écran de SnakeViz, on voit bien cet appel à __bool__(). On aurait dû le voir tout de suite !
En l’occurrence, ce test fait partie d’un bout de code de debug qui n’est même plus utilisé - d’ailleurs, si on regarde de plus près le reste de la
condition, on voit qu’elle ne peut être vraie que lorsqu’on fait tourner le code en local, quand DJANGO_ENV est positionné sur development.
On a enlevé le bout de code en question, et retesté la requête problématique en local :
$ hey -n 10 -c 1 "http://localhost:8000/api/ephemera/...
Summary:
...
Average: 0.1070 secs
...
100 millisecondes au lieu de 350. Autrement dit, c’est 3,5 fois plus rapide. Pas mal du tout !
Pour la petite histoire : le bout de code de debug en question était dans la méthode get_serializer, autrement dit, celle-là même que nous indiquait le flame graph de notre APM au début de notre analyse. Malheureusement, à ce moment-là, on avait totalement raté l’évaluation booléenne de ce QuerySet !
Après la bataille
On a déployé le “fix” en préprod, ce qui a divisé la durée des requêtes par 5 :
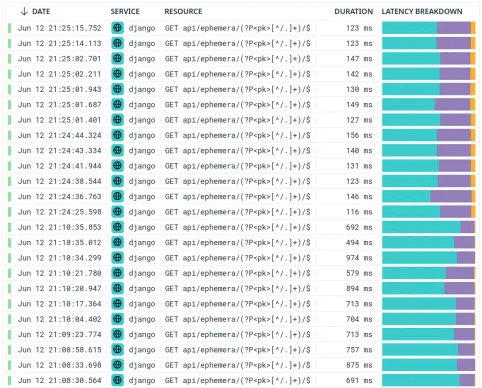
Puis le fix est parti en prod, avec des résultats similaires.
Mais le plus beau dans cette histoire, c’est qu’on va maintenant pouvoir utiliser la même technique de profiling sur d’autres requêtes.
Ce qu’il faut retenir
Évaluer un QuerySet comme une valeur booléenne exécute la requête correspondante (ça, c’est clairement indiqué dans la doc de l’API des QuerySet et peut parfois construire des instances de modèle pour chaque valeur renvoyée par la requête (ça, c’était moins clair, et on se demande toujours si c’est normal ou pas ; naïvement, on pourrait se dire qu’il suffirait de regarder si le QuerySet renvoie au moins une ligne).
La vérité n’est pas toujours ailleurs : quand un outil semble nous dire quelque chose de bizarre ou anormal, ça vaut le coup de regarder de plus près plutôt que de zapper et passer à la suite. Au tout début de l’enquête, on a ignoré des indices importants. Au final, on est quand même retombés sur nos pieds, grâce à l’utilisation d’outils complémentaires pour rattraper ce qu’on avait raté.
Simuler des requêtes Django est relativement facile, et la technique qu’on a utilisée ici (avec django.test et django.urls) est probablement utilisable avec n’importe quelle
requête Django - qu’on utilise DRF ou pas. L’idée générale peut s’adapter à n’importe quel framework et même d’autres langages.
Reproduire un problème en local c’est très utile, car cela nous permet de déployer une batterie de techniques pas toujours élégantes (print(), breakpoint()…) mais rapides
et efficaces. Ici, on a instrumenté la classe de base de l’ORM Django afin de voir quelles instances étaient créées, et ajouté un point d’arrêt conditionnel au programme. On n’aurait certainement pas fait ça sur un environnement de production. Et même en préproduction, cela n’aurait pas été aussi pratique et rapide.
Le code qui n’est plus utilisé, c’est mieux de le retirer plutôt que de le laisser là en attendant qu’il pose des problèmes mystérieux comme celui qu’on vient de voir. Mais bon, en pratique, tout le monde passe par là un jour ou l’autre : on ajoute un workaround ou une petite bidouille pour nous aider à dénicher un bug bizarre, et on oublie de remettre les choses au propre quand on a fini. C’est d’ailleurs pour ça que faire ce genre d’analyse en local, ça a du bon : ça nous évite de devoir passer par la grande boucle édition / commit / déploiement / test / et on recommence. Comme ça, quand on a trouvé d’où vient le problème, on commit juste ce qu’il faut, sans embarquer nos dizaines (voire centaines) de lignes de tests.
C’est tout ! Encore une fois, le bug qu’on a déniché était très spécifique à notre environnement. En revanche, on espère que la technique présentée ici pourra vous être utile dans d’autres circonstances et vous permettra de vous aussi résoudre des problèmes de performances dans vos applications.
Merci d’avoir tout lu, et si ce post vous a été utile, allez jeter un œil aux cartes postales sur EphemeraSearch. Et on se retrouve très bientôt ici pour de nouveaux articles sur nos thématiques plus habituelles : l’infrastructure, le DevOps et le cloud native !
Ne ratez pas nos prochains articles DevOps et Cloud Native! Suivez Enix sur Linkedin!